التعلم الموجه لتحليل الصور | الوحدة الأولى | الدرس الأول
التعلم الموجه لتحليل الصور هو عنوان الدرس الأول من الوحدة الرابعة التي تحمل اسم “التعرُّف على الصور” في الفصل الدراسي الثاني من مقرر “تقنية رقمية 1”.
نتعرف في هذا الموضوع على أحد مجالات الذكاء الاصطناعي وهو “رؤية الحاسب”، وكيفية استخدام هذا المجال في تحليل الصور، وتمكين الآلات من رؤية العالم كما يراه البشر، ومن ثم اتخاذ القرارات أو القيام بإجراءات.

التعلم الموجه
ركز جيدًا في قراءة أهداف التعلُّم، واحرص على مراجعتها، والتأكُّد من تحصيلها؛ لتحقيق أكبر استفادة وفهم للموضوع.
أهداف التعلُّم
- معرفة التعلم الموجه في رؤية الحاسب.
- تحميل الصور ومعالجتها الأولية باستخدام لغة بايثون.
- التنبؤ بدون هندسة الخصائص باستخدام لغة بايثون.
- التنبؤ بانتقاء الخصائص باستخدام لغة بايثون.
- التنبؤ باستخدام الشبكات العصبية باستخدام لغة بايثون.
- التنبؤ باستخدام الشبكات العصبية الترشيحية باستخدام لغة بايثون.
- معرفة التعلم المنقول.
هيا لنبدأ!
التعلم الموجه في رؤية الحاسب (Supervised Learning for Computer Vision)
تُعدُّ رؤية الحاسب (Computer Vision) مجالًا فرعيًا من مجالات الذكاء الاصطناعي، والذي يُركِّز على تعليم أجهزة الحاسب طريقة تفسير العالم المرئي وفهمه.
كيف تتم هذه العملية؟
يتم استخدام الصور الرقمية ومقاطع الفيديو لتدريب الآلات على التعرُّف على المعلومات المرئية وتحليلها،
مثل: الأشياء والأشخاص والمَشاهِد، ومن ثم تمكين الآلات من رؤية العالم كما يراه البشر، واستخدام هذه المعلومات في اتخاذ قرارات أو القيام بإجراءات.
من التطبيقات التي يتم استخدامها فيها رؤية الحاسب:
- التصوير الطبي
تستطيع رؤية الحاسب مساعدة الأطباء والمختصين في الرعاية الصحية على تشخيص الأمراض من خلال تحليل الصور الطبية (المدخلات)، مثل: الأشعّة السينية، والتصوير بالرنين المغناطيسي، والأشعّة المقطعية.
- المركبات ذاتية القيادة
تَستخدِم السيارات ذاتية القيادة والطائرات المسيَّرة رؤية الحاسب للتعرُّف على إشارات المرور وأشكال الطرق وطرق المشاة والعقبات في الطريق والجو، وذلك حتى تتمكن من التنقل بأمان وكفاءة.
- ضبط الجودة
يتم استخدام رؤية الحاسب لفحص المنتجات وتحديد عيوب التصنيع، وذلك في مختلف أنواع الصناعات، مثل: صناعة السيارات، والإلكترونيات، والمنسوجات.
-
الروبوتية
يتم استخدام رؤية الحاسب لمساعدة الروبوتات على التنقل والتفاعل مع بيئتها، عن طريق التعرُّف على الأشياء والتعامل معها.

التعلم الموجه
تعرَّف على المزيد من المعلومات عن رؤية الحاسب من خلال الرابط التالي:
والآن سنتعرف على كيفية تحليل الصور؟!
يعتبر التعلم الموجه وغير الموجه نوعين رئيسين من تعلُّم الآلة، ويستخدمان بطريقة شائعة في تطبيقات رؤية الحاسب.
يتضمن كلا النوعين خوارزميات تدريب على مجموعة كبيرة من الصور الرقمية أو مقاطع الفيديو؛
لكي تتمكن الآلات من التعرُّف على المعلومات المرئية وتفسيرها.
وتتمثل الفروقات بين التعلم الموجه والغير موجه في:
التعلم غير الموجه
- يتضمن خوارزميات تدريب على مجموعات غير معنونة (لا توجد فيها عناوين أو فئات صريحة).
- تتعلم الخوارزمية تحديد الأنماط المتشابهة في البيانات.
- على سبيل المثال: من الممكن استخدام الخوارزمية لتجميع الصور المتشابهة بناءً على السمات المشتركة بينها، مثل: اللون أو النقش (Texture) أو الشكل.
التعلم الموجه
التعلم الموجه
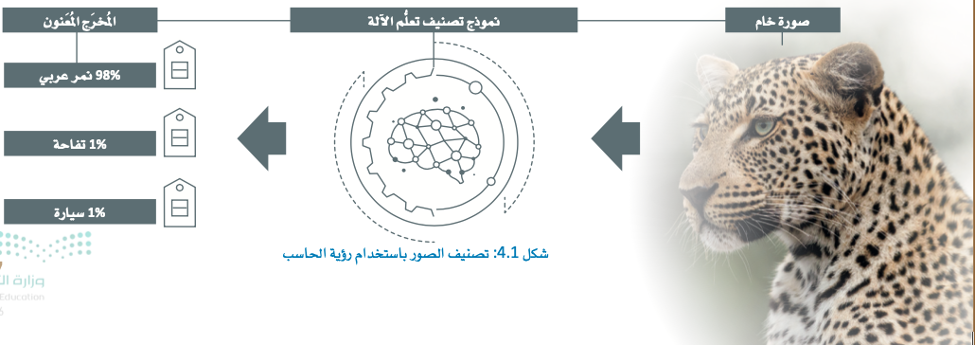
- يتضمن تدريب الخوارزميات على مجموعات بيانات معنونة (كل صورة أو مقطع فيديو تحت عنوان معين).
- تقوم الخوارزمية بعد ذلك بالتعرُّف على أنماط وخصائص كل عنوان؛ لتتمكن من تصنيف الصور أو مقاطع الفيديو الجديدة.
- على سبيل المثال: تدريب الخوارزمية على التعرُّف على سلالات مختلفة من القطط بناءً على الصور المُعنونة لكل سلاسة.
سيتم التركيز في هذا الموضوع على التعلُّم الموجَّه، هيا بنا!
تشمل عملية التعلم الموجه عادةً على 4 خطوات، وهي:
جمع البيانات، وعنونتها، والتدريب عليها، ثم الاختبار.
أثناء جمع البيانات ووضع المسميات، يتم تجميع الصور أو مقاطع الفيديو وتنظّم في مجموعة البيانات،
ثم يتم عنونة كل صورة أو مقطع فيديو بعنوان صنف أو فئة، مثل نسر (Eagle) أو قطة (Cat).
ثم أثناء مرحلة التدريب يتم استخدام خوارزمية تعلُّم الآلة “لتتعلَّم” الأنماط والسمات المرتبطة بكل صنف أو فئة، وكلما زادت بيانات التدريب التي تحصل عليها الخوارزمية كلما أصبحت أكثر دقة في التعرف على الفئات المختلفة في مجموعة البيانات.
بعد الانتهاء من تدريب النموذج، يتم اختباره على مجموعة مغايرة للتي تدرَّب عليها لتقييم أدائه، ولابد أن تختلف مجموعة التدريب عن مجموعة الاختبار؛ للتأكُّد من قدرة النموذج على التعميم على البيانات الجديدة.
لاحظ أن
تشبه العملية السابقة العملية المتَّبعة في التعلُّم الموجه لأنواع مختلفة من البيانات مثل النصوص، ولكن في البيانات المرئية يكون الأمر أكثر صعوبة، وذلك للعديد من البيانات، نستعرضها في الجدول التالي:

التعلم الموجه
نتيجة لهذه التعقيدات، يتطلب التصنيف الفعال أساليب مخصصة.
سنتناول في هذه الوحدة التقنيات التي تَستخدِم الخصائص اللونية والهندسية للصور، بالإضافة إلى أساليب تعلُّم الآلة المتقدمة القائمة على الشبكات العصبية.
ونبدأ بكيفية استخدام لغة البايثون (Python) في:
- تحميل مجموعة بيانات من الصور المعَنوَنة.
- تحويل الصور إلى صيغة رقمية يمكن أن تستخدِمها خوارزميات رؤية الحاسب.
- تقسيم البيانات الرقمية إلى مجموعات بيانات للتدريب، ومجموعات بيانات للاختبار.
- تحليل البيانات، لاستخراج أنماط وخصائص مفيدة.
- استخدام البيانات المستخلصة؛ لتدريب نماذج التصنيف التي يُمكِن استخدامها للتنبؤ بعناوين الصور الجديدة.
تحميل الصور ومعالجتها الأولية (Loading and Preprocessing Image) | التعلم الموجه
- يستورد المقطع البرمجي التالي مجموعة من المكتبات يتم استخدامها لتحميل الصور من مجموعة بيانات LHI-Animal-Faces (وجوه_الحيوانات) وتحويلها إلى صيغة رقمية.

التعلم الموجه
- تتطلب خوارزميات التعلم الموجه أن تكون كل الصور في مجموعة البيانات لها نفس الأبعاد، ولذلك فإن المقطع البرمجي التالي يقرأ الصور من input_folder (مجلد المُدخَلات)، ويقوم بتغيير أبعاد الصور ليكون لها نفس الطول والعرض.



- تنشئ دالة imread ( ) تنسيق ألوان للصورة يُعرَف باسم “RGB“، لأنه يسمح بتمثيل مجموعة كبيرة من الألوان.
يحتوي RGB على 3 مكونات رئيسية للألوان، وهي:
R = Red (الأحمر)، G = Green (الأخضر)، B = Blue (الأزرق).
يتم تمثيل كل بكسل بـ 3 قنوات لونية (قناة اللون الأحمر، قناة اللون الأخضر، قناة اللون الأزرق)، كل قناة تحتوي على ثمانية بت (8-bit)، ويمكن أن يأخذ البكسل قيمة بين 0 و255.
“يتم أيضًا تعريف التنسيق 255-0 باسم تنسيق البايت بدون إشارة (Unsigned Byte)”
- يتيح الجمع بين هذه القنوات الثلاث تمثيل مجموعة واسعة من الألوان في البكسل، على سبيل المثال، البكسل ذو القيمة:
– (255, 0, 0) سيكون لونه أحمر بالكامل.
– (0, 255, 0) سيكون لونه أخضر بالكامل.
– (0, 0, 255) سيكون لونه أزرق بالكامل.
– (255, 255, 255) سيكون لونه أبيض بالكامل.
– (0, 0, 0) سيكون لونه أسود بالكامل. - في نظام RGB، يتم ترتيب قيم البكسل في شبكة ثنائية الأبعاد، تحتوي على صفوف وأعمدة تُمثِّل إحداثيات X وY للبكسلات في الصورة، كما يتم الإشارة إلى هذه الشبكة باسم مصفوفة الصور (Image Matrix).
ضع في اعتبارك هذه الصورة والمقطع البرمجي المرتبط بها أدناه.

التعلم الموجه
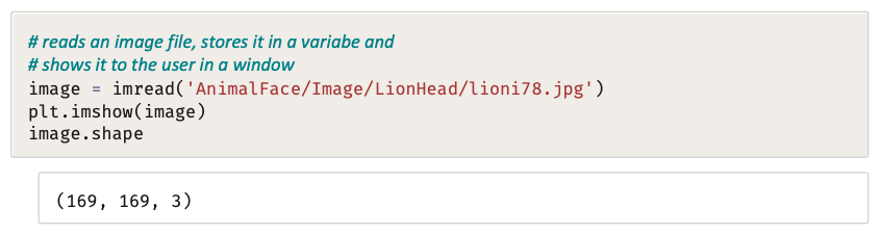
تكشف طباعة شكل الصورة عن مصفوفة 169 Î 169، بإجمالي 28,561 بكسل، ويمثِّل الرقم 3 القنوات الثلاث (أحمر/ أخضر/ أزرق) لنظام ألوان RGB.
على سبيل المثال، سيطبع المقطع البرمجي التالي قيمة الألوان للبكسل الأول من هذه الصورة.

لاحظ أن
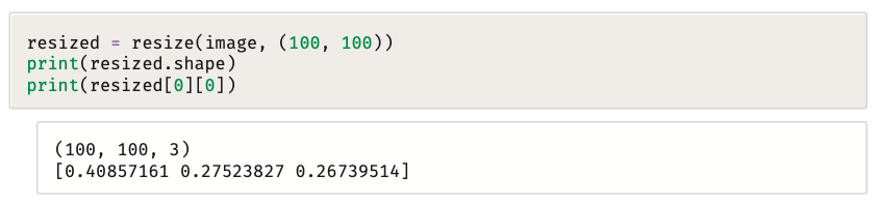
يؤدي تغيير الحجم إلى تحويل الصور من تنسيق RGB الممثل بالأرقام (100, 100, 3)، إلى تنسيق مستنِد على عدد غير حقيقي (Float Based) الممثل بالأرقام المعروضة تحت تمثيل الـ RGB.
لاحظ أيضًا
بالرغم من تغيير حجم الصورة إلى مصفوفة ذات أبعاد 100 * 100، إلا أن قيم القنوات الثلاث RGB لكل بكسل تم تسويتها (Normalized) لتكون قيمتها بين 0 و1، ومن الممكن إعادة تحويلها مرة أخرى إلى تنسيق “البايت بدون إشارة” باستخدام المقطع البرمجي التالي:

لاحظ كذلك أن
من الآثار الشائعة الناتجة عن تغيير الحجم، اختلاف قيم الألوان RGB للبكسل الذي تم تغيير حجمه اختلافًا بسيطًا عن الصورة الأصلية،
وعند الطباعة يتبين أن الصورة أقل وضوحًا – كما هو موضح بالصورة –، وهذا ناتج عن ضغط المصفوفة 169 * 169 إلى تنسيق 100 * 100.
- تحقق قبل بدء التدريب على خوارزميات التعلم الموجه من أن جميع الصورة الموجودة في مجموعة البيانات مطابقة للتنسيق (100, 100, 3)، ويمكن القيام بذلك باستخدام المقطع البرمجي التالي..

التعلم الموجه

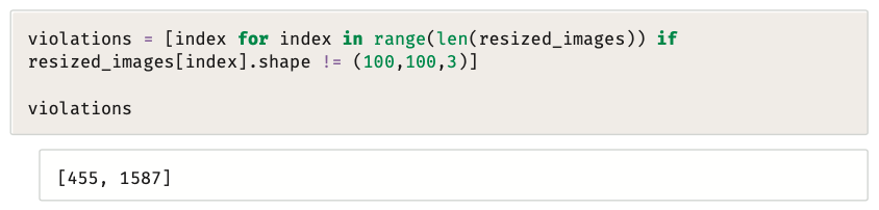
يتضح من خلال تطبيق المقطع البرمجي أن هناك صورتين غير مطابقتين لتلك الصيغة، وهذا غير متوقع!،
لأن الدالة resize_image ( ) تم تطبيقها على جميع الصور.
طباعة الصور
يقوم المقطعان البرمجيان التاليان بطباعة الصورتين، بالإضافة إلى أبعادهما واسمي ملفيهما:
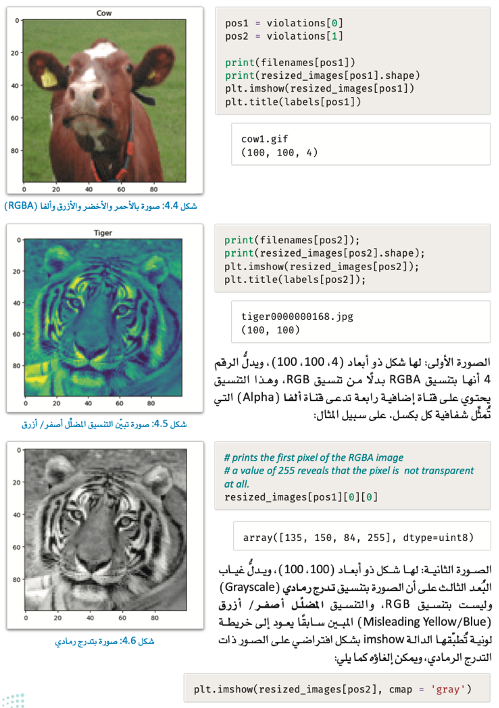
التعلم الموجه
لاحظ
صور التدرُّج الرمادي لها قناة واحدة فقط (بدلًا من قنوات RGB الثلاث)، وقيمة كل بكسل عبارة عن رقم واحد يتراوح من 0 إلى 255.
– البكسل ذو القيمة 0 يمثل اللون الأسود.
– البكسل ذو القيمة 255 يمثل اللون الأبيض.
على سبيل المثال:

- وكاختبار إضافي لجودة البيانات، يمكنك استخدام المقطع البرمجي التالي لحساب تكرار عنوان كل صورة حيوان في مجموعة البيانات..

تحتوي مجموعة البيانات على صور حيوانات وصور أخرى للطبيعة، والتي يكشفها العداد (Counter)، وتكون عبارة عن فئة بعنوان الطبيعة (Nat)، وعندما تقوم بكشف سريع يتضح أن هذه الفئة ذات قيم متطرفة (Outlier) تحتوي على مناظر طبيعية ولا يوجد بها أي وجه لأي حيوان.
مهم للغاية
يقوم المقطع البرمجي التالي بإزالة صورة RGBA وصورة التدرج الرمادي وصور الطبيعة (Nat) من قوائم أسماء الملفات، والعناوين، والصور التي تم تغيير حجمها (حيث أنك لا تحتاجها في مجموعة البيانات).

تتمثل الخطوة التالية في تحويل resized_image (الصور_المُعدَّل حجمها) وقوائم العناوين إلى مصفوفات نمباي (Numpy) حسب ما تتوقعه العديد من خوارزميات رؤية الحاسب.
يُستخدَم المقطع البرمجي التالي المُتغيِّرات (X, Y) التي يتم استخدامها عادةً لتمثيل البيانات والعناوين على التوالي في مهام التعلم الموجه:
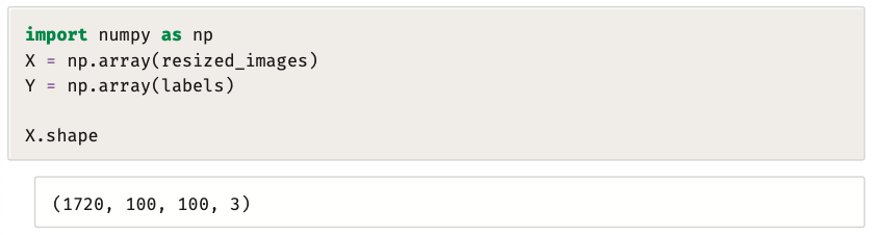
يوضِّح شكل مجموعة بيانات X النهائية احتوائها على 1720 صورة بتنسيق RGB، بناءً على عدد القنوات، وجميها بحجم 100 * 100 (أي 10,000 بكسل).
أخيرًا، من الممكن استخدام دالة train_test_split( ) من مكتبة Sklearn لتقسيم مجموعة البيانات إلى مجموعة تدريب ومجموعة اختبار..

كما أنه من الجيد إعادة ترتيب البيانات عشوائيًا قبل إجراء أي تحليل، وذلك من خلال ضبط Shuffle = True (تفعيل إعادة الترتيب)، نظرًا لأن المجلدات تم تحميلها مجلدًا تلو الآخر، وبالتالي الصور من كل مجلد تم جمعها معًا، وقد يؤدي ذلك إلى تضليل العديد من الخوارزميات، خاصةً في مجال رؤية الحاسب.
قم بمراجعة المعلومات حتى هذا الجزء من الموضوع من خلال الرابط التالي:
التنبؤ بدون هندسة الخصائص (Prediction without Feature Engineering)
تحتوي كل نقطة بيانات في مجموعة البيانات المرئية على تنسيق ثلاثي الأبعاد، مثال: (100, 100, 3)،
وهو ليس بالتنسيق القياسي أحادي البعد الذي تتوقعه العديد من خوارزميات تعلُّم الآلة.

التعلم الموجه
لذلك من الممكن استخدام المقطع البرمجي التالي لتسطيح (Flatten) كل صورة في متَّجَه أحادي البُعد (مثال 100 Î 100 Î 3= 30,000 قيمة).
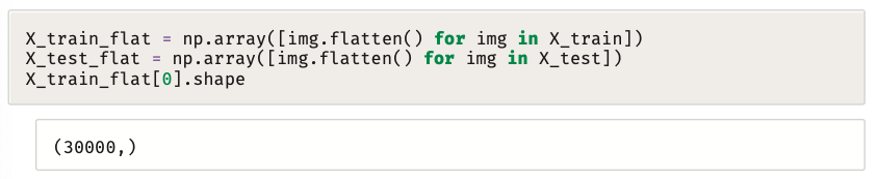
من الممكن استخدام هذا التنسيق المسطح مع أي خوارزمية تصنيف قياسية، دون بذل أي مجهود إضافي لهندسة خصائص تنبؤية أخرى.
يوضح المقطع البرمجي التالي مثالًا على هندسة الخصائص لبيانات صورة، ويستخدم مصنِّف بايز الساذج (Naive Bayes – NB) الذي تم استخدامه سابقًا لتصنيف البيانات النصية:
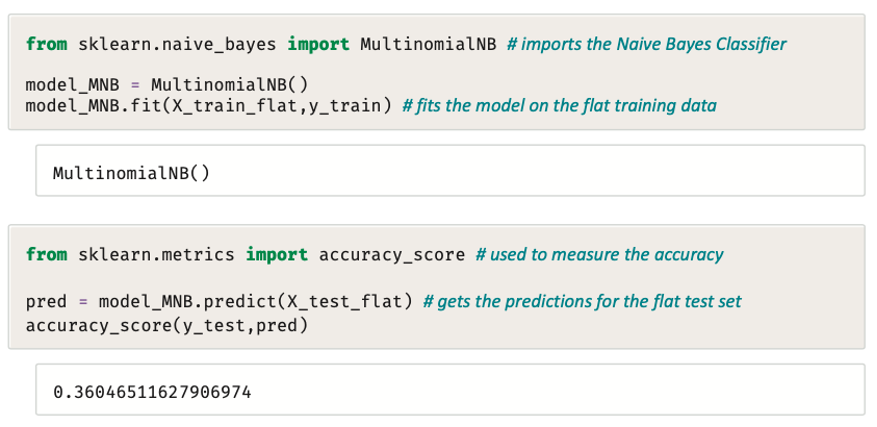
يعرض المقطع البرمجي التالي مصفوفة الدقة (Confusion Matrix) الخاصة بالنتائج؛ لإعطاء رؤية إضافية..
التعلم الموجه
التعلم الموجه
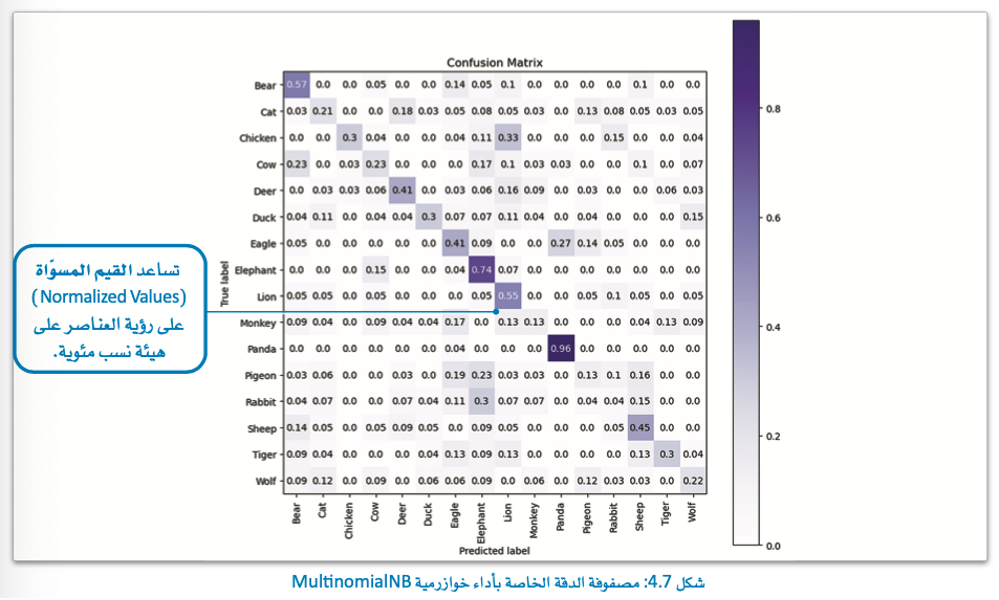
دقة خوارزمية بايز
تحقق خوارزمية بايز الساذجة متعددة الحدود (MultinominalNB) دقة تقارب 30%، وعلى الرغم من أنها نسبة قليلة، إلا أنه يجب النظر إليها في ضوء أن مجموعة البيانات تضم 20 عنوانًا مختلفًا.
ولو افترضنا أن مجموعة البيانات متوازية نسبيًا أي يضم كل عنوان فيها نسبة 1/20 من البيانات، فإن المصنِّف العشوائي الذي يقوم بتخصيص عنوانًا لكل نقطة اختبار بشكل عشوائي، سيحقق دقة تبلغ حوالي 5% (1/20 = 5%).
لذلك ستكون دقة خوارزمية بايز (30%) أعلى بـ 6 مرات من التخمين العشوائي.
مع ذلك، من الممكن تحسين هذه الدقة تحسينًا ملحوظًا، وتؤكد مصفوفة الدقة أن هناك مجالًا للتحسين.
على سبيل المثال: غالبًا ما يخطئ نموذج بايز الساذج في تصنيف الحَمَام على أنها نسور، وتصنيف الذئاب على أنها قطط.
وهنا تبرز أسهل طريقة لتحسين النتائج، وهي ترك البيانات كما هي، والتجريب باستخدام مصنِّفات مختلفة،
ومن النماذج التي ثبت أنها تعمل بشكل جيد مع بيانات الصورة المُحوَّلة إلى متَّجهات نموذج،
هو مصنِّف الانحدار التدريجي العشوائي (SGDClassifier) من مكتبة Sklearn.
حيث يعمل نموذج SGDClassifier أثناء التدريب على ضبط أوزان النموذج بناءً على بيانات التدريب، وبالتالي التقليل من دالة الخسارة (Loss Function)، وهي الدالة التي تقيس الفرق بين العناوين المتوقَّعة والعناوين الحقيقية في بيانات التدريب.

التعلم الموجه
يستخدِم المقطع البرمجي التالي مصنِّف SGDClassifier لتدريب نموذج على مجموعة بيانات مسطحة:
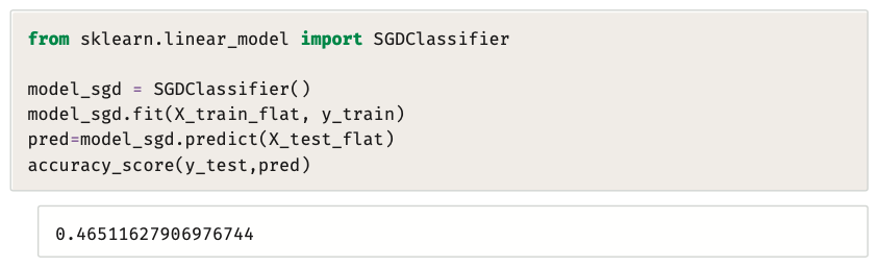
يُحقِّق مصنِّف SGDClassifier دقة أعلى بشكل ملحوظ تزيد عن 46%، وذلك رغم تدريبه على نفس البيانات التي تدرَّب عليها مصنِّف MultinominalNB.
يدل ذلك على فائدة تجريب خوارزميات تصنيف مختلفة؛ حتى تجد خوارزمية تتناسب مع مجموعة البيانات التي تعمل عليها.
ومن المهم معرفة نقاط القوة والضعف لكل خوارزمية، فعلى سبيل المثال: خوارزمية SGDClassifier تعمل بشكل أفضل عند تحجيم بيانات الإدخال وتوحيد الخصائص، لهذا السبب ستستخدِم التحجيم القياسي في نموذجك.
يستخدم المقطع البرمجي التالي أداة المحجِّم القياسي (StandardScaler) من مكتبة Sklearn:
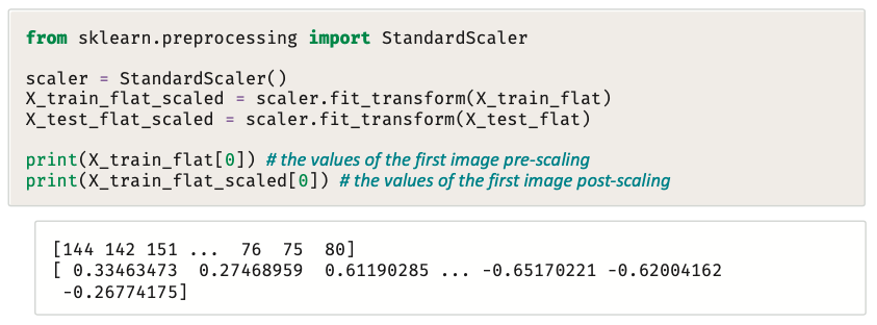
بإمكانك الآن تدريب نموذج جديد واختباره على مجموعة البيانات التي تم تحجيمها.

التعلم الموجه
تدل النتائج على تحسُّن الدقة بعد التحجيم (49% تقريبًا)، ومن المحتمل أن يحدث تحسين إضافي عند تجريب خوارزميات أخرى وضبط متغيراتها؛ عندما تكون متناسبة بشكل أفضل مع مجموعة البيانات.
التنبؤ بانتقاء الخصائص (Prediction with Feature Selection)
كان التركيز في القسم السابق من الموضوع على تدريب النماذج عن طريق تسطيح البيانات؛ بينما يركز هذا القسم على كيفية تحويل البيانات الأصلية لهندسة الخائص الذكية التي تلتقط الصفات الرئيسة لبيانات الصورة.
على وجه التحديد، يشرح هذا القسم استخدام تقنية المُخطَّط التكراري للتدرجات الموجَّهة (Histogram of Oriented Gradients –HOG).

التعلم الموجه
تتمثل الخطوة الأولى في استخدام هندسة HOG في تحليل الصور من تنسيق RGB إلى صور ذات تدرُّج رمادي.
من الممكن القيام بذلك باستخدام الدالة rgb2gray من مكتبة sckit-image:


التعلم الموجه
تم تغيير شكل الصور من تنسيق RGB المُستنِد إلى 100 * 100 * 3 إلى تنسيق 100 * 100..
تتمثل الخطوة التالية في إنشاء خصائص المُخطَّط التكراري للتدرجات الموجَّهة لكل صورة في البيانات،
ومن الممكن تحقيق ذلك من خلال دالة hog ( ) من مكتبة sckit-image.
يوضِّح المقطع البرمجي التالي مثالًا على الصورة الأولى في مجموعة بيانات التدريب..
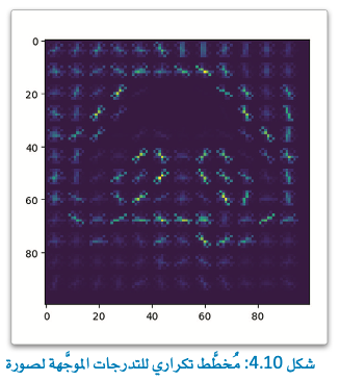
Hog_vector هو مُتَّجَه أحادي البُعد ذو 8,100 قيمة عددية، من الممكن استخدامها لتمثيل الصورة، ويَظهر التمثيل البصري لهذا المُتَّجَه باستخدام:

يصوِّر هذا التمثيل الجديد:
- حدود الأشكال الأساسية في الصورة.
- يحذف التفاصيل الأخرى.
وبالتالي يركز على الأجزاء المفيدة التي تساعد المُصنِّف على أن يقوم بالتنبؤ.
يطبِّق المقطع البرمجي التالي هذا التغيير على كل الصور سواء في مجموعة التدريب أو الاختبار..

بإمكانك الآن تدريب SGDClassifier على هذا التمثيل الجديد..

لاحظ ارتفاع نسبة الدقة إلى أكثر من 74%.

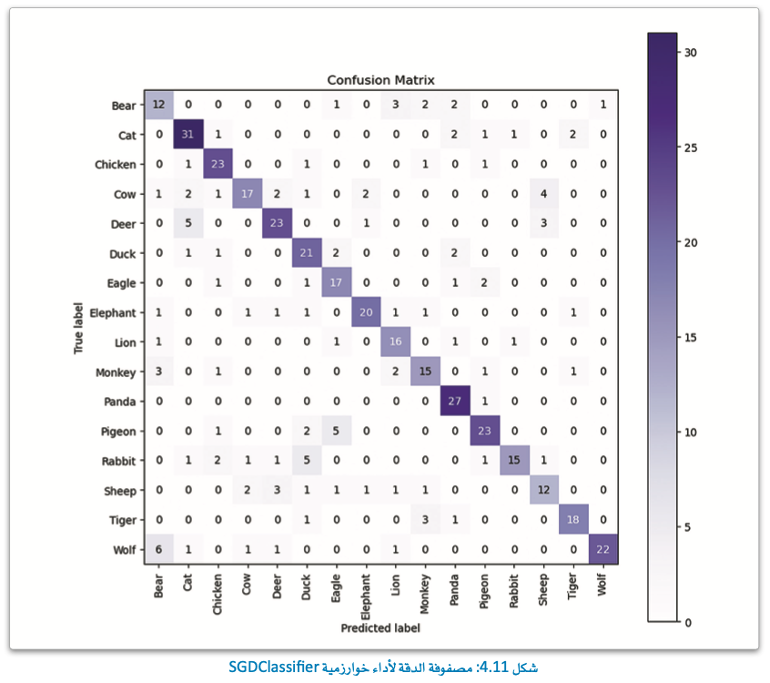
كما يتضح التحسُّن في مصفوفة الدقة المُحدَّثة التي تشمل عددًا أقل من الأخطاء (التنبؤات الإيجابية الخاطئة)، ويوضح ذلك أهمية استخدام تقنيات رؤية الحاسب لهندسة خصائص ذكية تلتقط الصفات المرئية المُختلفة للبيانات.
بإمكانك مراجعة محتويات الموضوع بدايةً من عنوان “التنبؤ بدون هندسة الخصائص” وحتى أخر قسم “التنبؤ بانتقاء الخصائص” من خلال الرابط التالي:
التنبؤ باستخدام الشبكات العصبية (Prediction Using Neural Networks) | التعلم الموجه
تتعلم في هذا القسم كيفية استخدام الشبكات العصبية لتصميم مصنِّفات مخصصة لبيانات الصور،
واستخدام مكتبات TensorFlow وKeras لهذا الهدف، وكيف يُمكِنها التفوق على التقنيات عالية الفاعلية مثل المخطط التكراري للتدرجات الموجهة.

التعلم الموجه
وللتعرُّف على هاتين المكتبتين تابع التالي:
- مكتبة TensorFlow:
هي مكتبة منخفضة المستوى توفِّر مجموعة واسعة من أدوات تعلُّم الآلة والذكاء الاصطناعي، وتسمح للمستخدمين بتعريف الحسابات العددية التي تتضمن متجهات متعددة الأبعاد (Tensors) ومعالجتها، وهي مصفوفات متعددة الأبعاد من البيانات.
- مكتبة Keras:
هي مكتبة ذات مستوى أعلى مبنية باستخدام مكتبة TensorFlow (أو مكتبات خلفية أخرى)، وتوفر واجهة أبسط لبناء النماذج وتدريبها، كما توفر مجموعة من النماذج والطبقات المُعرَّفة مسبقًا يُمكِن تجميعها بسهولة لبناء نموذج تعلُّم عميق، وتم تصميم مكتبة Keras لتكون سهلة الاستخدام؛ مما يجعلها خيارًا رائجًا للممارسين.
لحظة!
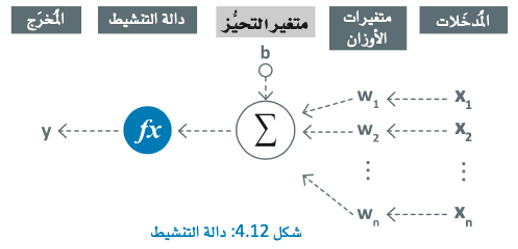
ماذا تعرف عن دوال التنشيط (Activation Functions)؟
هي دوال رياضية تطبق على مخرجَات كل خلية عصبية في الشبكة عصبية، كما تتميز بأنها تضيف خصائص غير خطية (Non-linear) للنموذج، وتسمح للشبكة بتعلُّم الأنماط المعقدة في البيانات.
التعلم الموجه
احرص على اختيار دالة التنشيط التي يمكن أن تؤثر على أداء الشبكة، حيث تتلقى الخلايا العصبية المُدخلات وتعالجها من خلال متغيرات الأوزان والتحيُّزات، وتنتج مخرَجات بناء على دالة التنشيط.
تنشأ الشبكات العصبية عن طريق ربط العديد من الخلايا العصبية معًا في طبقات، ويتم تدريبها على ضبط متغيرات الأوزان والتحيُّزات وتحسين أدائها بمرور الوقت.
يمكنك تثبيت مكتبات tensorflow وkeras من خلال المقطع البرمجي التالي:
يتم استخدام مكتبة Keras لإنشاء معمارية عصبية للصور، حيث تحول أولًا العناوين في y_train إلى تنسيق أعداد صحيحة، طبقًا لمتطلبات المكتبة..


الآن من الممكن استخدام أداة التتابع (Sequential) من مكتبة Keras لبناء شبكة عصبية في شكل طبقات متتابعة.

التعلم الموجه
ملخص النموذج
يكشف ملخص النموذج عن العدد الإجمالي للمُتغيِّرات التي يجب أن يتعلمها النموذج من خلال ضبطها على بيانات التدريب.
- المُدخَلات = 8,100 مُدخَل (هي أبعاد صور المُخطَّط التكراري للتدرجات الموجَّهة X_train_hog)
- الطبقة المخفية = 200 خلية عصبية (هي طبقة كثيفة متصلة بالمُدخَلات اتصالًا كاملًا)
المجموع = 200 * 8,100 = 1,620,000 وصلة موزونة يجب تعلُّم أوزانها (متغيِّراتها).
“يُضاف 200 مُتغيِّر تحيُّز (Bias) إضافي، بواقع مُتغيِّر لكل خلية عصبية في الطبقة المخفية”
- مُتغير التحيُّز
هو قيمة تُضاف إلى مُدخَلات كل خلية عصبية في الشبكة العصبية، وتُستخدَم لتوجيه دالة تنشيط الخلايا العصبية إلى الجانب السلبي أو الإيجابي؛ مما يسمح للشبكة بنمذجة علاقات أكثر تعقيدًا بين بيانات المُدخلات وعناوين المُخرَجات.
- طبقة المُخرَجات تحتوي على 16 خلية عصبية متصلة بالكامل بـ 200 خلية عصبية موجودة في الطبقة المخفية
المجموع = 200 * 16 = 3,200 وصلة موزونة
“يتم إضافة 16 مُتغيِّر تحيُّز إضافي، بواقع متغيِّر لكل خلية عصبية في طبقة المُخرَجات”
المجموع النهائي = 1,620,000 + 200 + 3,200 + 16 = 1,623,216
يتم استخدام المقطع البرمجي التالي لتجميع النموذج (Compile):

التعلم الموجه
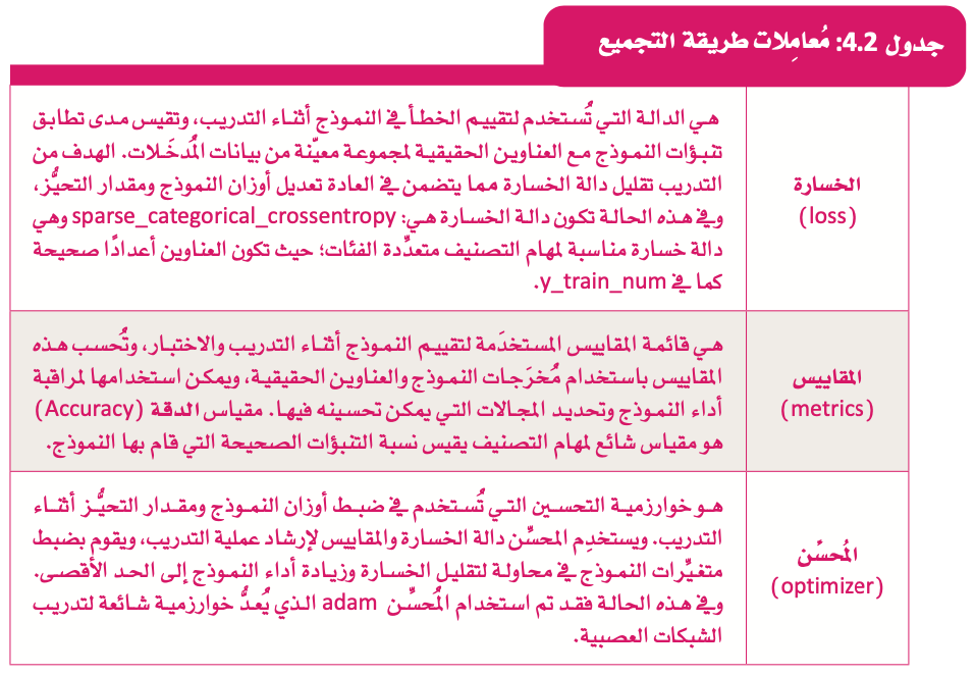
يتم استخدام دالة إعداد النموذج الذكي في مكتبة Keras والمعروفة بالتجميع (model.compile ( )) في عملية تحديد الخصائص الأساسية للنموذج الذكي وإعداده للتدريب والتحقق والتنبؤ، وتتخذ 3 معاملات رئيسة، هي:
التعلم الموجه
وأخيرًا، يتم استخدام دالة fit ( ) لتدريب النموذج على البيانات المتاحة..

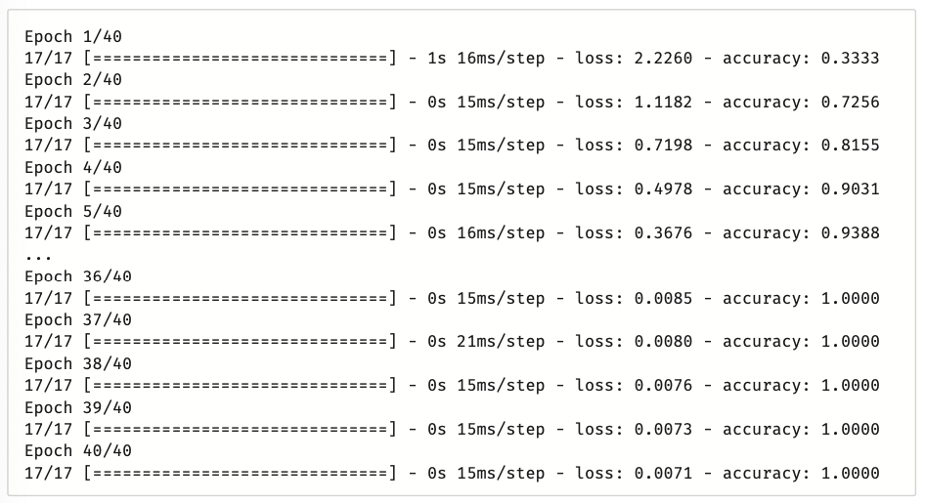
يتم استخدام دالة fit ( ) لتدريب النموذج على مجموعة معينة من بيانات الإدخال والعناوين،
وتتخذ 4 معاملات رئيسة، هي:
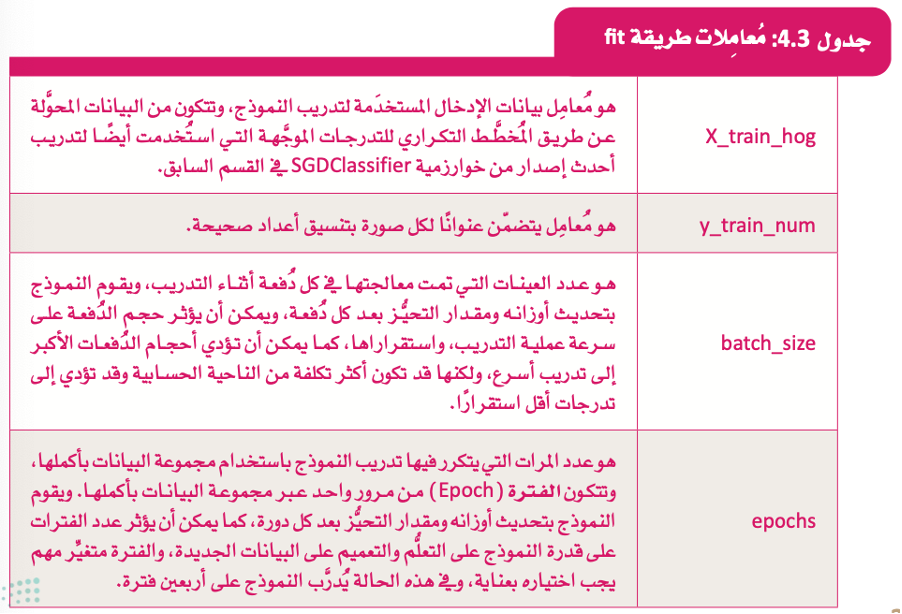
التعلم الموجه
الآن بإمكانك استخدام نموذج التدريب للتنبؤ بعناوين الصور في مجموعة الاختبار.
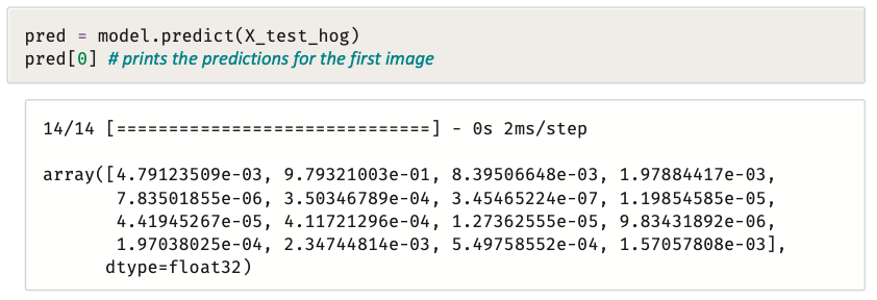
بينما تقوم دالة predict ( ) من مكتبة sklearn بإظهار العنوان الأكثر احتمالًا الذي يتنبأ بع المُصنِّف،
تقوم نفس الدالة من مكتبة Keras بإظهار احتمالات كل العناوين المرشحة، وهنا من الممكن استخدام دالة np.argmax ( ) لإظهار مؤشر العنوان الأكثر احتمالًا.

لاحظ أن
هذه الشبكة العصبية البسيطة تحقق دقة حوالي 75%، وهي دقة مشابهة لدقة SGDClassifier.
لكن ميزة المعماريات العصبية هو السماح بتجربة معماريات مختلفة للعثور على أفضل ما يناسب مجموعة بياناتك.
لاحظ كذلك
تم استخدام معمارية بسيطة تضم طبقة مخفية واحدة تحتوي على 200 خلية عصبية،
ويعُّد اختيار عدد الطبقات وعدد الخلايا العصبية لكل طبقة عناصر مهمة لتصميم الشبكة العصبية،
ولها تأثير كبير على أدائها (زيادة الطبقات الإضافية يجعل الشبكة أعمق،
وإضافة خلايا عصبية أكثر في نفس الطبقة يجعلها أوسع)،
ولكنها ليست الطريقة الوحيدة لتحسين الأداء، ففي بعض الحالات تحتاج إلى استخدام نوع مختلف أكثر فاعلية من معمارية الشبكة العصبية.
قم بمراجعة محتوى قسم “التنبؤ باستخدام الشبكات العصبية” من خلال الرابط التالي:
التنبؤ باستخدام الشبكات العصبية الترشيحية (Prediction Using Convolutional Neural Networks)
الشبكة العصبية الترشيحية هي أحد أنواع المعماريات التي تتناسب مع تصنيف الصور، وبما أنها تعالج بيانات الإدخال،
فإنها تقوم باستمرار بضبط متغيِّرات الفلاتر المرشَّحَة لاكتشاف الأنماط بناءً على البيانات التي تراها؛
حتى تتمكن من اكتشاف الخصائص المهمة بشكل أفضل،
ثم تنقل مخرجات كل طبقة إلى الطبقة التالية التي تكشف خصائص أكثر تعقيدًا إلى أن تقوم بإنتاج المخرجات النهائية.

بالرغم من فوائد الشبكات العصبية مثل CNN إلا أنه من المهم ملاحظة:
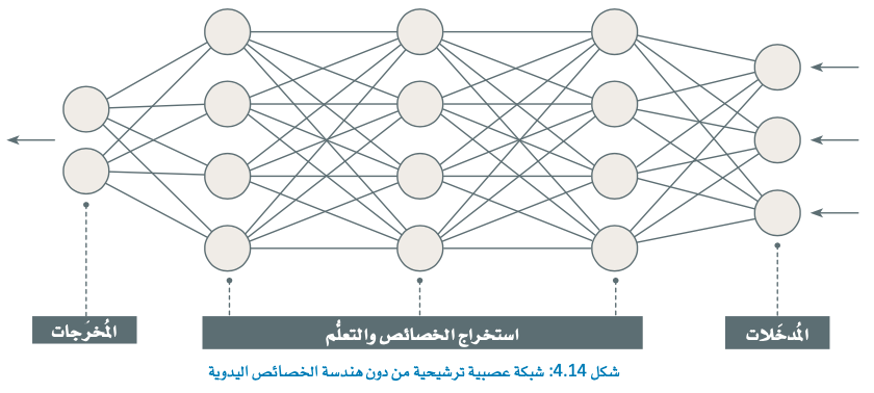
- تكمن قوة الشبكات العصبية الترشيحية في قدرتها على استخراج الخصائص المهمة ذات الصلة من الصور بشكل تلقائي، دون الحاجة إلى هندسة الخصائص اليدوية (Manual Feature Engineering).
- تحتوي المعماريات العصبية الأكثر تعقيدًا على المزيد من المتغيِّرات التي يجب تعلُّمها من البيانات أثناء التدريب، ويتطلب ذلك مجموعة بيانات تدريب أكبر قد لا تكون متاحة في بعض الحالات، وفي مثل هذه الحالات من غير المحتمل أن يكون إنشاء معمارية معقدة للغاية أمرًا فعَّالًا.
- على الرغم من أن الشبكات العصبية قد حققت بالفعل نتائج مبهرة في معالجة الصور والمهام الأخرى، إلا أنها لا تضمن تقديم أفضل أداء لجميع المشكلات ومجموعات البيانات.
- حتّى لو كانت معمارية الشبكة العصبية أفضل حل ممكن لمُهِمَّة محددة، فقد يستغرق الأمر كثيرًا من الوقت والجهد والموارد الحاسوبية لتجربة خيارات مختلفة إلى أن يتم العثور على هذه المعمارية. لذلك من الأفضل البدء بنماذج أبسط (لكنها لا تزال فعَّالة)، مثل: نموذج SGDClassifier وغيره من النماذج المتوفرة في المكتبات مثل: مكتبة sklearn، وبمجرد حصولك على أفضل تنبؤ لمجموعة البيانات ولا يُمكِن تحسين النماذج أكثر من ذلك، فإن التجريب على المعماريات العصبية الأخرى يُعدُّ خطوة ممتازة.
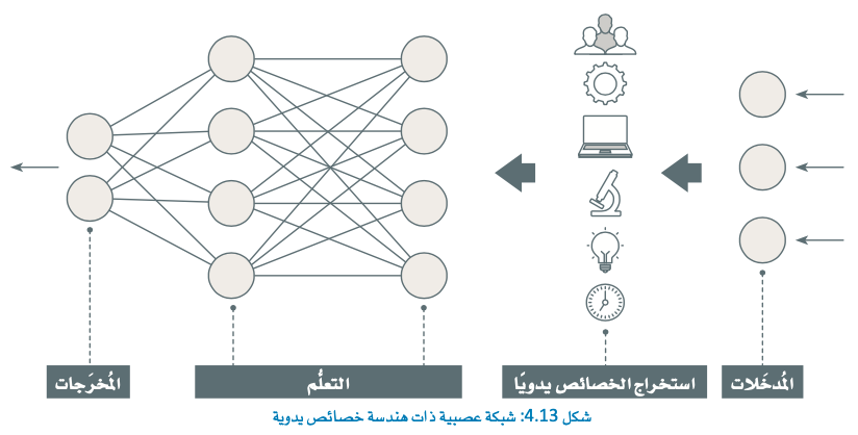
معلومة
من المزايا الأساسية للشبكات العصبية الترشيحية أنها جيدة جدًا في التعلُّم من كميات كبيرة من البيانات، ويمكنها في العادة أن تحقق مستويات عليا في دقة المهام، مثل: تصنيف الصور دون الحاجة إلى هندسة الخصائص اليدوية، مثل: المُخطَّط التكراري للتدرجات الموجَّهة.
التعلم الموجه
التعلُّم المنقول (Transfer Learning) | التعلم الموجه
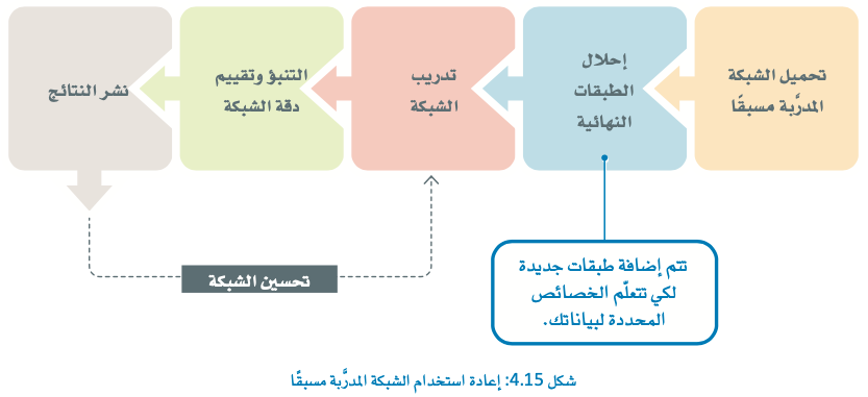
التعلُّم المنقول هو إعادة استخدام شبكة عصبية مدرَّبة مسبقًا في حل مهمة جديدة.

في سياق الشبكات العصبية الترشيحية يتضمن التعلُّم المنقول أخذ نموذج مدرَّب مسبقًا على مجموعة كبيرة من البيانات، وتشغيله على مجموعة بيانات جديدة،
فبدلًا من البدء من نقطة الصفر، يتيح Transfer Learning استخدام النماذج المُدرَّبة مسبقًا، أي التي تعلَّمت بالفعل خصائص مهمة،
مثل: الحواف، والأشكال، والنقوش من مجموعة بيانات التدريب.
قم بمراجعة محتوى الموضوع بدايةً من عنوان “الشبكات العصبية الترشيحية” وحتى أخر الموضوع من خلال الرابط التالي:
اختبر تحصيلك لمحتوى الموضوع من خلال الرابط التالي:
الواجب الإلكتروني
إلى هنا يكون قد انتهى موضوع “التعلم الموجه لتحليل الصور”، لا تنسوا مراجعة نواتج التعلُّم أعلى المقال، وانتظرونا في الموضوع القادم!