التعلم الموجه | الوحدة الثالثة | الدرس الأول

التعلم الموجه هو عنوان الدرس الأول من الوحدة الثالثة التي تحمل اسم “معالجة اللغات الطبيعية” في الفصل الدراسي الأول من مقرر “الذكاء الاصطناعي”.
ستتعرف في هذا الموضوع على استخدام التعلم الموجه لفهم النصوص، والتعرُّف على مفهوم تعلُّم الآلة وأقسامه، والمقارنة بين مزايا أنواع تعلُّم الآلة وعيوبها، وتطبيق تجهيز البيانات والمعالجة المُسبقة، وكيفية بناء خط أنابيب التنبؤ، وشرح متنبِّئات الصندوق الأسود، وتحسين البرمجة الاتّجاهية للنصوص، بالإضافة إلى استخدام مقياس تكرار المصطلح – تكرار المُستند العكسي في البرمجة الاتّجاهية للنصوص.

لذا قم بقراءة أهداف التعلُّم بعناية، ثم أعد قراءتها وتأكَّد من تحصيل كافة محتوياتها بعد انتهائك من دراسة الموضوع.
أهداف التعلُّم
- استخدام التعلُّم الموجَّه لفهم النصوص.
- معرفة تعلُّم الآلة.
- تحديد أقسام تعلُّم الآلة.
- المقارنة بين مزايا أنواع تعلُّم الآلة وعيوبها.
- تطبيق تجهيز البيانات والمعالجة المُسبقة.
- بناء خط أنابيب التنبؤ.
- شرح متنبئات الصندوق الأسود.
- تحسين البرمجة الاتّجاهية للنصوص.
- استخدام مقياس تكرار المصطلح – تكرار المُستند العكسي في البرمجة الاتّجاهية للنصوص.
هيا لنبدأ!
استخدام التعلُّم الموجَّه لفهم النصوص (Using Supervised Learning to Understand Text)
معالجة اللغات الطبيعية (Natural Language Processing – NLP) هي إحدى مجالات الذكاء الاصطناعي (AI) التي تركز على تمكين أجهزة الحاسب لتصبح قادرة على فهم اللغات البشرية وإنتاجها وتفسيرها.
ما هي المهام التي تقوم بها معالجة اللغات الطبيعية؟
- تصنيف النصوص.
- تحليل المشاعر.
- الترجمة الآلية.
- الإجابة على الأسئلة.
سيركز هذا الموضوع بشكل خاص على كيفية استخدام التعلم الموجه الذي يُعد أحد الأنواع الرئيسة لتعلم الآلة (Machine Learning – ML) في تحقيق الفهم والتنبؤ التلقائي لخصائص النصوص.
لقد تعلمت في الوحدة الأولى أن الذكاء الاصطناعي مصطلح يشمل كلاً من:
- تعلم الآلة.
- التعلم العميق.
كما يتضح في الشكل أدناه.

الذكاء الاصطناعي هو ذلك المجال الواسع من علوم الحاسب الذي يعني بابتكارات آلات ذكية بينما تعلم الآلة هو أحد فروع الذكاء الاصطناعي الذي يركز على تصميم الخوارزميات وبناء النماذج التي تمكن الآلة من التعلم من البيانات دون الحاجة إلى برمجتها بشكل صحيح.
تعريف هام
التعلُّم العميق (Deep Learning)
التعلُّم العميق هو أحد أنواع تعلُّم الآلة الذي يستخدِم الشبكات العصبية العميقة للتعلُّم تلقائيًا من مجموعات كبيرة من البيانات، فهو يسمح لأجهزة الحاسب بالتعرُّف على الأنماط واتّخاذ القرارات بطريقة تحاكي الإنسان، عبر تصميم نماذج معقدة من البيانات.
لمعرفة المزيد من المعلومات عن التعلُّم العميق، قم بالاطّلاع على الرابط التالي:
تعلم الآلة (Machine Learning)
ما المقصود بتعلم الآلة؟
هو أحد فروع الذكاء الاصطناعي المعني بتطوير الخوارزميات التي تُمكن أجهزة الحاسب من التعلم من البيانات المدخلة، بدلاً من اتباع التعليمات البرمجية الصريحة.
مهام تعلم الآلة:
- تدريب نماذج الحاسب للتعرف على الأنماط.
- القيام بالتنبؤات وفقًا للبيانات المدخلة مما يسمح للنموذج بتحسين الدقة مع مرور الوقت.
كذلك يتيح للآلة أداء مهام متعددة مثل:
- التصنيف.
- الانحدار.
- التجميع.
- تقديم التوصيات دون الحاجة إلى برمجة الآلة بكل مهمة على حدة.
يمكن تصنيف تعلم الآلة إلى ثلاثة أنواع رئيسة:
- التعلم الموجه (Supervised Learning)
هي نوع من الآلة تتعلم فيه الخوارزمية من بيانات تدريب معنونة (Labelled) بهدف القيام بالتنبؤات حول بيانات جديدة غير موجودة في مجموعة التدريب أو الاختبار كما هو موضح في الشكل ومن الأمثلة عليه:
- تصنيف الصور (Image Classification)، مثل: التعرف على الكائنات في الصور.
- كشف الاحتيال (Fraud Detection)، مثل: تحديد المعاملات المالية المشبوهة.
- تصفية البريد الالكتروني العشوائي (Spam Filtering)، مثل: تحديد رسائل البريد الالكتروني غير المرغوب بها.

لمعرفة المزيد من المعلومات عن التعلم الموجه، ثم بالاطّلاع على الرابط التالي:
- التعلم غير الموجه (Unsupervised Learning)
هو نوع من تعلم الآلة تعمل فيه الخوارزمية بموجب بيانات غير معنونة (Unlabeled) في محاولة لإيجاد الأنماط والعلاقات بين البيانات، من الأمثلة عليها:
- الكشف عن الاختلاف (Anomaly Detection)، مثل: تحديد الأنماط غير العادية في البيانات.
- التجميع (Clustering)، مثل: تجميع البيانات ذات الخصائص المتشابهة.
- تقليص الأبعاد (Dimensionally Reduction)، مثل: اختيار الأبعاد المستخدمة للحد من تعقيد البيانات.
لمعرفة المزيد من المعلومات عن التعلم غير الموجه، قم بالاطّلاع على الرابط التالي:
- التعلم المعزز (Reinforcement Learning)
هو نوع من تعلم الآلة تتفاعل فيه الآلة مع البيئة المحيطة وتتعلم عبر المحاولة والخطأ أو تلقي المكافأة والعقاب. من الأمثلة عليها:
- لعب الألعاب، مثل: لعبة الشطرنج أو لعبة قو (GO).
- الروبوتية، مثل: تعليم الروبوت كيف يتنقل في البيئة المحيطة به.
- تخصيص الموارد، مثل: تحسين استخدام الموارد في شبكة ما.
لمعرفة المزيد من المعلومات عن التعلم المعزز، قم بالاطّلاع على الرابط التالي:
الجدول التالي يلخص مزايا أنواع تعلُّم الآلة وعيوبها.

التعلم الموجه (Supervised Learning)
هو أحد أنواع تعلم الآلة الذي يعتمد على استخدام البيانات المعنونة لتدريب الخوارزميات للقيام بالتنبؤات.
يتم تدريب الخوارزمية على مجموعة من البيانات المعنونة ثم اختبارها على مجموعة بيانات جديدة لم تكن جزءًا من بيانات التدريب.
يُستخدم التعلم الموجه عادة في معالجة اللغات الطبيعية للقيام بمهام مثل:
- تصنيف النصوص.
- تحليل المشاعر.
- التعرف على الكيانات المسماة (Named Entity Recognition – NER).

في هذه المهام يتم تدريب الخوارزمية على مجموعة من البيانات المعنونة، حيث يتم إدراج كل مثال تحت عنوان التصنيف المناسب أو المشاعر المناسبة.
يُطلق على عملية التعلم الموجه اسم الانحدار (Recognition) عندما تكون القيم التي تتنبأ بها الآلة رقمية، بينما يُطلق عليها اسم التصنيف (Classification) عندما تكون القيم متقطعة.
تعريف هام
التعلُّم الموجَّه (Supervised Learning)
ستستخدِم في التعلُّم الموجَّه مجموعات البيانات المُعنوَنة والمُنظمة بشكل يدوي لتدريب خوارزميات الحاسب على التنبؤ بالقيم الجديدة.
الانحدار (Recognition)
على سبيل المثال، قد يستخدم الانحدار في التنبؤ بسعر بيع المنزل وفقًا لمساحته وموقعه وعدد غرف النوم فيه. كما يمكن استخدامه في التنبؤ بحجم الطلب على أحد المنتجات استنادًا إلى بيانات المبيعات التاريخية وحجم الإنفاق الإعلاني وفي مجال اللغات الطبيعية يستخدم الانحدار الخطي النصوص المدخلة المتوفرة للتنبؤ بتقييم الجمهور للفيلم أو مدى التفاعل مع المنشورات الخاصة به على وسائل التواصل الاجتماعي.
التصنيف Classification
يستخدم التصنيف في التطبيقات مثل: تشخصي الحالات الطبية وفقًا للأعراض ونتائج الفحوصات. وعندما يتعلق الأمر بفهم النصوص، يمكن استخدام التعلم الموجه في تصنفي النصوص المدخلة إلى مئات أو عناوين أو التنبؤ بها بناء على الكلمات أو العبارات الموجودة في المستند.
على سبيل المثال، يمكن تدريب نموذج التعلم الموجه لتصنيف رسائل البريد الالكتروني إلى رسائل مزعجة أو غير مزعجة وفقًا للكلمات أو العبارات المستخدمة في رسالة البريد الالكتروني.
يعد تصنيف المشاعر أحد التطبيقات الشهيرة كذلك، حيث يمكن التنبؤ بالانطباع العام حول مستند ما سواء كان ايجابيًا أو سلبيًا وسيستخدم هذا التطبيق كمثال عملي في هذه الوحدة، لشرح كل خطوات عملية بناء أو استخدام نموذج التعلم الموجه بشكل شامل من بداية رحلة التعلم حتى نهايتها.
في هذه الوحدة ستستخدم مجموعة بيانات من مراجعات الأفلام على موقع IMDb.com الشهير ستجد البيانات مقسمة إلى مجموعتين:
- المجموعة الأولى ستستخدم لتدريب النموذج.
- المجموعة الثانية لاختبار أداء النموذج في البداية.
لابد أن تحمل البيانات إلى DataFarme لذا عليك استخدام مكتبة بانداس بايثون (Pandas Python) والتي استخدمتها سابقًا.
مكتبة بانداس هي إحدى الأدوات الشهيرة التي تستخدم للتعامل مع جداول البيانات التعليمات البرمجية التالية ستقوم باستيراد المكتبة إلى البرنامج، ثم تحميل مجموعتي البيانات.


الخطوة التالية هي إسناد أعمدة النص والقيم إلى متغيرات مستقلة في أمثلة التدريب والاختبار الممثلة كمجموعة بيانات DataFrame كما يلي:

بإمكانك مراجعة محتوى موضوع “التعلم الموجه” من بدايته وحتى نهاية هذا القسم، من خلال الرابط التالي:
تجهيز البيانات والمعالجة والمُسبقة (Data Preparation and Pre-Processing)
على الرغم من أن تنسيق النص الأولي كما في الشكل أدناه بديهي للقارئ البشري، إلا أن خوارزميات التعلم الموجه لا تستطيع التعامل معه بصورته الحالية.
فبدلاً من ذلك، تحتاج الخوارزميات إلى تحويل هذه المستندات إلى تنسيق متجه رقمي (Numeric Vector) فيما يعرف بعملية البرمجة الاتجاهية (Vectorization) ويمكن تطبيق عملية البرمجة الاتجاهية بعدة طرائق مختلفة وتتميز بأن لها تأثيرًا ايجابيًا كبيرًا على أداء النموذج المُدرَّب.
مكتبة سكيلرن sklearn Library
سيتم بناء النموذج الموجه باستخدام مكتبة سكليرن وتعرف كذلك باسم مكتبة سايكيت ليرن (Scikit Learn) وهي مكتبة شهيرة في بايثون تختص بتعلم الآلة.
توفر المكتبة مجموعة من الأدوات والخوارزميات لأداء مهام متعددة مثل:
- التصنيف.
- الانحدار.
- التجميع.
- تقليص الأبعاد.
إحدى الأدوات المفيدة في مكتبة سكليرن هي أداة تسمى (Count Vectorizer).
ويمكن استخدامها في تهيئة عملية المعالجة وتمثيل البيانات النصية بالمتجهات.
أداة Counter Vectorizer
تستخدم في تحويل مجموعة من المستندات النصية إلى مصفوفة من رموز متعددة، حيث يمثل كل صف مستند وكل عمود رمزًا خاصًا.
قد تكون الرموز كلمات فردية أو عبارات أو بنيات أكثر تعقيدًا تقوم بالتقاط الأنماط المتعددة من البيانات النصية الأساسية.
تشير المدخلات في المصفوفة إلى عدد مرات ظهور الرمز في كل مستند ويعرف ذلك أيضًا باسم تمثيل حقيبة الكلمات “bag-of-word BOW” حيث يتجاهل ترتيب الكلمات في النص مع المحافظة على تكرارها فيه على الرغم من أن تمثيل حقيبة الكلمات هو تبسيط شديد للغة البشرية، إلا أنه يحقق نتائج تنافسية للغاية عند التطبيق العملي.

تعريف هام
البرمجة الاتجاهية (Vectorization)
البرمجة الاتجاهية هي علمية تحويل السلاسل النصية المكوَّنة من الكلمات أو العبارات (النص) إلى متَّجَه متجانس من الأرقام الحقيقية يُستخدَم لترميز خصائص النص باستخدام تنسيق تفهمه خوارزميات تعلُّم الآلة.
يستخدم المقطع البرمجي التالي أداة Counter Vectorize لتمثيل مجموعة من بيانات التدريب IMDb بالمتجهات:

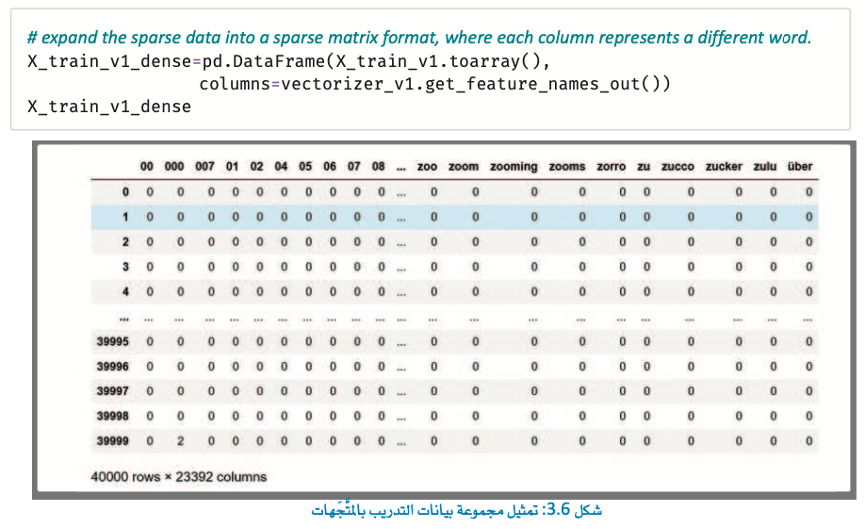
يعبر هذا التنسيق الكثيف (Dense) للمصفوفة عن 40.000 تقييم ومراجعة فلم في بيانات التدريب.
تحتوي المصفوفة على عمود لكل كلمة تظهر في 10 مراجعات على الأقل (منفذة بواسطة المتغير min_df). كما يتضح بالأعلى ينتج عن ذلك 23.392 عمودًا، مرتبة في ترتيب أبجدي رقمي.
يعبر مدخل المصفوفة في الموضع [i] عن عدد المرات التي تظهر فيها كلمة في المراجعة .أ. وعلى الرغم من إمكانية استخدام هذه المصفوفة مباشرة من قبل خوارزمية التعلم الموجه إلا أنها غير فعالة من حيث استخدام الذاكرة، والسبب في ذلك أن الغالبية العظمى من المدخلات في هذه المصفوفة تساوي 0 وهذا يحدث لأن نسبة ضئيلة جدًا فقط من بين 23.392 كلمة محتملة ستظهر فعليًا في كل مراجعة.
لمعالجة هذا القصور تخزن أداة Counter Vectorizeالبيانات الممثلة بالمتجهات في مصفوفة متباعدة حيث تحتفظ فقط بالمدخلات غير الصفرية في كل عمود.
يستخدم المقطع البرمجي بالأسفل الدالة getsizeof() التي تحدد حجم الكائنات في لغة بايثون (python) بالبايت (Byte) لتوضيح مدى التوفير في الذاكرة عند استخدام المصفوفة المتباعدة لبيانات IMDb:

بحسب المتوقع تحتاج المصفوفة المتباعدة إلى ذاكرة أقل بكثير وتحديدًا 0.000048 ميجابايت. بينما تشغل المصفوفة الكثيفة 7 جيجا بايت كما أن هذه المصفوفة لن تستخدم مرة أخرى وبالتالي يمكن حذفها بتوفير هذا الحجم الكبير من الذاكرة:

بِناء خط أنابيب التنبؤ (Building a Prediction Pipeline)
الآن بعد أن تمكنت من تمثيل بيانات التدريب بالمتجهات فإن الخطوة التالية هي بناء خط أنابيب التنبؤ الأول.
أحد الأمثلة على المصنفات المستخدمة للتنبؤ بالنص هو المصنف بايز الساذج
(Naive Bayes Classifier) يستخدم هذا المصنف احتمالات الكلمات أو العبارات المحددة الواردة في النص للتنبؤ باحتمال انتمائه إلى تصنيف محدد.
جاءت كلمة الساذج (Naive) في اسم المصنف من افتراض أن وجود كلمة بعينها في النص مستقل عن وجود أي كلمة أخرى وهذا افتراض قوي ولكنه يسمح بتدريب الخوارزمية بسرعة وفعالية كبيرة.
تعريف هام
المُصنِّف (Classifier)
المُصنِّف في تعلُّم الآلة هو نموذج يُستخدَم لتمييز نقاط البيانات في فئات أو تصنيفات مختلفة. الهدف من المُصنِّف هو التعلُّم من بيانات التدريب المُعنوَنة، ومن ثَمَّ القيام بالتنبؤات حول قيم التصنيف لبيانات جديدة.
يستخدم المقطع البرمجي التالي تطبيق مصنف بايز الساذج (Multinomial) من مكتبة سكليرن (SKlearn Library) لتدريب نموذج التعلم الموجه على بيانات التدريب بالمتجهات IMDb بالمتجهات:

على سبيل المثال، سينتج هذا المقطع البرمجي مصفوفة نتائج يرمز فيها الرقم 1 للتقييم الإيجابي والرقم 0 التقييم السلبي.

يتنبأ خط الأنابيب بشكل صحيح بالقيمة الايجابية والسلبية للتقييمين الأول والثاني على التوالي، يمكن استخدام الدالة المضمنة predict_proba() لتحديد جميع الاحتمالات التي يقوم بها خط الأنابيب بتخصيصها لكل واحدة من القيمتين المحتملتين العنصر الأول هو احتمال تعيين 0 والعنصر الثاني هو احتمال تعيين 1:
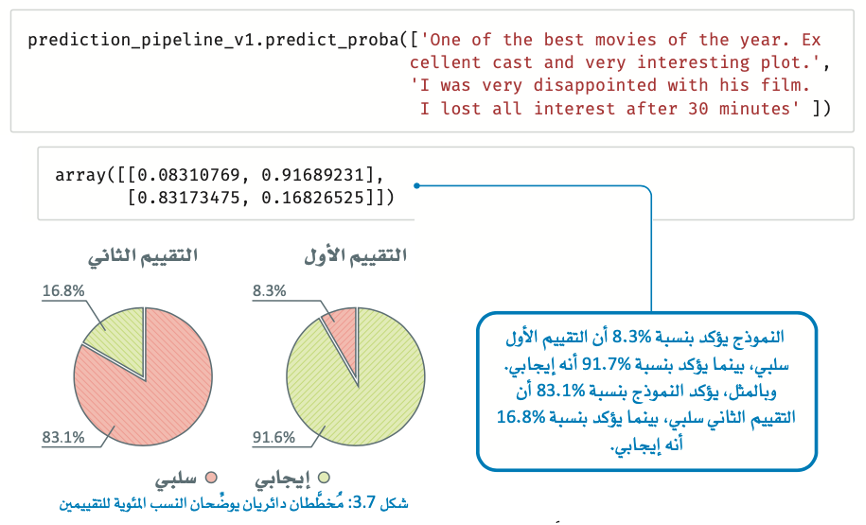
الخطوة التالية هي اختبار دقة خط الأنابيب الجديد في تصنيف التقييمات في مجموعة بيانات اختبار IMDb.
المخرج هو مصفوفة تشمل جميع قيم نتائج تصنيف التقييمات الواردة في بيانات الاختبار:

توفر لغة بايثون العديد من الأدوات لتحليل وتصوير نتائج خطوط أنابيب التصنيف، تشمل الأمثلة دالة accuracy_score() من مكتبة سكليرن وتمثيل مصفوفة الدقة
(Confusion Matrix) من مكتبة سايكيت بلوت (scikit_plot). وهناك مقاييس تقييم أخرى مثل: الدقة والاستدعاء والنوعية والحساسية مقاييس درجة F1 وفقًا لحالة الاستخدام التي يمكن حسابها من مصفوفة الدقة.
المخرج التالي هو تقريب دقيق لدرجة التنبؤ:


تحتوي مصفوفة الدقة على عدد التصنيفات الحقيقية مقابل المتوقعة.
في مهمة التصنيف الثنائية مثل (مسألة احتواء قيمتين، الموجود في مهمة IMDb) ستحتوي مصفوفة الدقة على أربع خلايا:
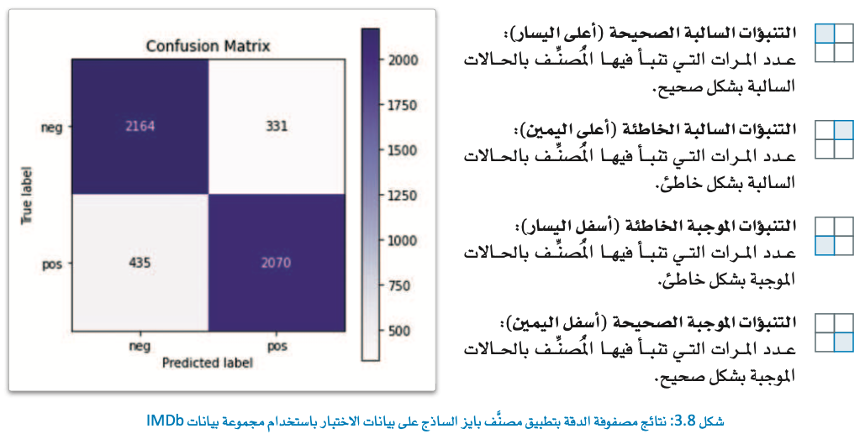
تظهر النتائج أنه على الرغم من أن خط الأنابيب الأول يحقق دقة تنافسية تصل إلى 84.68% إلا أنه لا يزال يخطئ في تصنيف مئات التقييمات.
فهناك 331 تنبؤًا غير صحيح في الربع الأيمن العلوي و 435 تنبؤًا غير صحيح في الربع الأيسر السفلي بإجمالي 766 تنبؤًا غير صحيح.
الخطوة الأولى نحو تحسين الأداء هي دراسة سلوك خط أنابيب التنبؤ، لمعرفة كيف يقوم بمعالجة النص وفهمه.
تعريف هام
الدقة (Accuracy)
الدقة هي نسبة التنبؤات الصحيحة إلى إجمالي عدد التنبؤات.
الدقة = (التنبؤات الموجبة الصحيحة + التنبؤات السالبة الصحيحة) / (التنبؤات الموجبة الصحيحة + التنبؤات السالبة الصحيحة + التنبؤات الموجبة الخاطئة + التنبؤات السالبة الخاطئة)
شرح متنبِّئات الصندوق الأسود (Explaining Black-Box Predictors)
يستخدم مصنف بايز الساذج الصيغ الرياضية البسيطة لتجميع احتمالات آلاف الكلمات وتقديم تنبؤاتها.
بالرغم من بساطة النموذج إلا أنه لا يزال غير قادر على تقديم شرح بسيط ومباشر لكيفية قيام النموذج بتوقع القيمة الموجية أو السالبة لجزء محدد من النص. قارن ذلك مع مصنفات شجرة القرار الأكثر وضوحًا، حيث يتم تمثيل القواعد التي تعلمها النموذج في الهيكل الشجري، مما يُسهل فهم كيف يقوم المصنف بالتنبؤات.
يتيح هيكل الشجرة كذلك الحصول على تصور مرئي للقرارات المتخذة في كل فرع مما يكون مفيدًا في فهم العلاقات بين الخصائص المدخلة والمتغير المستهدف.
الافتقار إلى قدرة التفسير يعد تحديًا كبيرًا في الخوارزميات الأكثر تعقيدًا، كتلك المستندة إلى التجميعات مثل: توليفات من الخوارزميات المتعددة أو الشبكات العصبية فبدون القدرة على التفسير تتقلص خوارزميات التعلم الموجه إلى متنبئات الصندوق الأسود على الرغم من أنها تفهم النص بشكل كافٍ للتنبؤ بالقيم، إلا أنها لا تزال غير قادرة على تفسير كيف يقوم باتخاذ القرار.
أجريت العديد من الأبحاث للتغلب على هذه التحديات بتصميم وسائل قادرة على التفسير تستطيع فهم نماذج الصندوق.
واحدة من الوسائل الأكثر شهرة هي النموذج المحايد المحلي القابل للتفسير والشرح (Local Interpretable Model-Agnostic Explanations – LIME).
النموذج المحايد المحلي القابل للتفسير والشرح (Local Interpretable Model-Agnostic Explanations – LIME)
هو طريقة لتفسير التنبؤات التي قامت بها نماذج الصندوق الأسود وذلك من خلال:
النظر في نقطة بيانات واحدة في وقت محدد.
إجراء تغييرات بسيطة عليها المعرفة كيف يؤثر ذلك على قدرة تنبؤ النموذج.
ثم تستخدم هذه المعلومات لتدريب نموذج مفهوم وبسيط مثل الانحدار الخطي على تفسير هذه التنبؤات بالنسبة للبيانات النصية.
يقوم النموذج المحايد المحلي القابل للتفسير والشرح بالتعرف على الكلمات أو العبارات التي لها الأثر الأكبر على القيام بالتنبؤات.
فيما يلي، تطبيق بلغة البايثون يوضح ذلك:

كما هو متوقع، يقدم نموذج التنبؤ تنبؤًا سلبيًا مؤكدًا بدرجة كبيرة في هذا المثال البسيط.

يمكن الحصول على تصور مرئي أكثر دقة على النحو التالي:

يزيد المعامل السالب من احتمالية التصنيف السالب، بينما يقلل المعامل الموجب منه.
على سبيل المثال، الكلمات:
- Horrible (فظيع).
- Terrible (مربع).
- Boring (ممل).
لها التأثير الأقوى على قرار النموذج بالتنبؤ بالقيمة السالبة.
الكلمة very (جدًا) دفعت النموذج قليلاً في اتجاه آخر ايجابي، ولكنها لم تكن كافية لتغيير القرار. بالنسبة للمراقب البشري، قد يبدو غريبًا أن الكلمات الخالية من المشاعر مثل plot (الحبكة الدرامية) أو was (كان) لها معاملات مرتفعة نسبيًا ومع ذلك من الضروري أن تتذكر أن تعلم الآلة لا يتبع دومًا الوعي البشري السليم.
وقد تكشف هذه المعاملات المرتفعة بالفعل عن قصور في منطق الخوارزمية وقد تكون مسؤولة عن بعض أخطاء نموذج التنبؤ.
على نحو بديل، يعد نموذج التنبؤ بمثابة مؤشر على الأنماط التنبؤية الكامنة والغنية في الوقت نفسه بالمعلومات.
على سبيل المثال، قد يبدو الواقع وكأن المقيمين البشريين أكثر استخدامًا لكلمة plot (الحبكة الدرامية) أو صيغة الماضي was (كان) عند الحديث في سياق سلبي، ويمكن لمكتبة النموذج المحايد المحلي القابل للتفسير والشرح (LIME) في لغو البايثون تصوير الشروحات بطرائق أخرى على سبيل المثال:

التقييم المستخدم في المثال السابق كان سلبيًا بشكل واضح ويسهل التنبؤ به. خذ بعين الاعتبار التقييم التالي الأكثر صعوبة والذي يمكن أن يتسبب في تذبذب دقة الخوارزمية وهو مأخوذ من مجموعة بيانات الاختبار IMDb:


على الرغم من أن هذا التقييم إيجابي بشكل واضح، إلا أن نموذج التنبؤ قدم تنبؤًا سلبيًا مؤكدًا للغاية باحتمالية وصلت إلى 83%. يمكن الآن استخدام المفسر لتوضيح السبب وراء اتخاذ نموذج التنبؤ مثل هذا القرار الخاطئ:

على الرغم من أن نموذج التنبؤ يستنبط التأثير الإيجابي لبعض الكلمات على نحو صحيح مثل:
- Beautifully (بشكل جميل).
- Great (رائع).
- Superb (مدهش).
إلا أنه يتخذ في النهاية قرارًا سلبيًا استنادًا إلى العديد من الكلمات التي يبدو أنها لا تعبر بشكل واضح عن المشاعر السلبية مثل:
- Asano (أسانو).
- Asian (آسيوي).
- Movie (فيلم).
- Acting (تمثيل).
وهذا يوضح العيوب الكبيرة في المنطق الذي يستخدمه نموذج التنبؤ لتصنيف المفردات الواردة في نصوص التقييمات المقدمة.
القسم التالي يوضح كيف أن تحسين هذا المنطق يمكن أن يطور من أداء نموذج التنبؤ إلى حد كبير.
لمشاهدة محتوى موضوع “التعلم الموجه” من بداية قسم “تجهيز البيانات والمعالجة المسبقة” وحتى نهاية هذا القسم، من خلال الرابط التالي:
بإمكانك مراجعة محتوى موضوع “التعلم الموجه” بدايةً من عنوان “تجهيز البيانات والمعالجة والمُسبقة” وحتى نهاية هذا القسم، من خلال الرابط التالي:
تحسين البرمجة الاتجاهية للنصوص (Improving Text Vectorization)
استخدم الإصدار الأول لخط أنابيب التنبؤ أداة CounterVectorize لحساب عدد المرات التي تظهر فيها كل كلمة في كل تقييم. تتجاهل هذه المنهجية حقيقتين أساسيتين حول اللغات البشرية:
- قد يتغير معنى الكلمة وأهميتها حسب الكلمات المستخدمة معها.
- تكرار الكلمة في المستند لا يُعد دومًا تمثيلاً دقيقًا لأهميتها.
على سبيل المثال، على الرغم من أن تكرار كلمة great (رائع) مرتين قد يمثل مؤشرًا إيجابيًا في مستند يحتوي على 100 كلمة إلا أنه يمثل مؤشرًا أقل أهمية بكثير في مستند يحتوي على 1000 كلمة.
سيشرح هذا الجزء كيفية تحسين البرمجة الاتجاهية للنصوص لأخذ هاتين الحقيقتين في عين الاعتبار يستدعي المقطع البرمجي التالي ثلاث مكتبات مختلفى بلغة البايثون، ستستخدم لتحقيق ذلك:
- Nltk وجينسم (Gensim): تستخدم هاتان المكتبتان الشهيرتان في مهام معالجة اللغات الطبيعية المتنوعة.
- re تستخدم هذه المكتبة في البحث عن النصوص في مستقل، ومعالجتها باستخدام التعبيرات النمطية.

تعريف هام
التعبير النمطي (Regular Expression)
التعبير النمطي هو نمط نص يُستخدَم لمطابقة ولمعالجة سلاسل النصوص وتقديم طريقة موجزة ومرنة لتحديد أنماط النصوص، كما تُستخدَم على نطاق واسع في معالجة النصوص وتحليل البيانات.
تحديد العبارات Detecting Phrases
يمكن استخدام الدالة الاتية لتقسيم مستند محدد إلى قائمة من الجمل المقسمة، حيث يمكن تمثيل كل جملة مقسمة بقائمة من الكلمات:

دالة sent_tokenize() من مكتبة nltk تقسم المستند إلى قائمة من الجمل.
تعريف هام
التقسيم (Tokenization)
يقصد به: عملية تقسيم البيانات النصية إلى أجزاء مثل كلمات، وجُمل، ورموز، وعناصر أخرى يُطلق عليها الرموز (Tokens).
بعد ذلك، يتم كتابة كل جملة بأحرف صغيرة وتغذيتها إلى دالة findall من مكتبة re لتقوم بتحديد تكرارات التعبيرات المنطقية ‘\b\w+\b’.
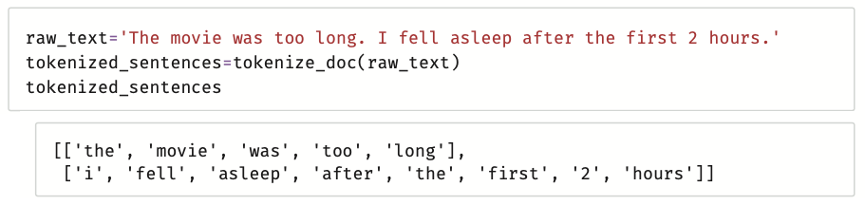
ستختبرها على السلسلة النصية الموجودة في متغير raw_text في السياق التالي:
- \w تتطابق مع كل الرموز الأبجدية الرقمية (0-9, A-Z, a-z) والشرطية السفلية.
- \w+ تستخدم للبحث عن واحد أو أكثر من رموز \w. لذلك، في السلسلة النصية hello123_world(مرحبا123_العالم)، النمط \w+ سيتطابق مع الكلمات hello (مرحبا) و 123 و world (العالم).
- \b تمثل الفاصل (boundry) بين رمز \w ورمز ليس \w. وكذلك في بداية أو نهاية السلسلة النصية المعطاة. على سبيل المثال، سوف يتطابق النمط \bcat\b مع الكلمة cat (القطة) في السلسلة النصية The category is pets (فئة الحيوانات الأليفة).
أدناه مثالاً على التقسيم باستخدام tokenize_doc().
يمكن تجميع الدالة tokenize_doc() مع أداة العبارات من مكتبة Gensim لإنشاء نموذج العبارة وهو نموذج يمكنه التعرف على العبارات المكونة من عدة كلمات في جملة معطاة. يستخدم المقطع البرمجي التالي بيانات التدريب IMDbالخاصة (X_train_text) لبناء مثل هذا النموذج:

كما هو موضح بالأعلى، تستخدم الدالة Phrases() أربعة متغيرات:
- قائمة الجمل المقسمة من مجموعة النصوص المعطاة.
- قائمة بالكلمات الإنجليزية الشائعة التي تظهر بصورة متكررة في العبارات مثل (of, The) وليس لها أي قيمة موجبة أو سالبة ولكن يمكنها إضفاء المشاعر حسب السياق، ولذلك يتم التعامل معها بصورة مختلفة.
- تستخدم دالة تسجيل النقاط لتحديد ما إذا كان تضمين مجموعة من الكلمات في العبارة نفسها واجبًا، المقطع البرمجي بالأعلى يستخدم مقياس المعلومات النقطية المشتركية المعاير (Normalized Pointwise Mutual Information- NPMI) لهذا الغرض، يستند هذا المقياس على تكرار توارد الكلمات في العبارة المرشحة وتكون قيمته بين -1 ويرمز إلى الاستقلالية الكاملة (Completed Independence) و 1+ يرمز إلى التوارد الكامل (Complete Co-occurrence).
- في حدود تسجيل دالة النقاط يتم تجاهل العبارات ذات النقاط الأقل ومن الناحية العلمية يمكن ضبط هذه الحدود لتحديد القيمة التي تعطي أفضل النتائج في التطبيقات النهائية مثل: النمذجة التنبؤية.
تحول دالة freeze() نموذج العبارة إلى تنسيق غير قابل للتغيير أي مجمد (Frozen) لكنه أكثر سرعة.
عند تطبيقها على الحملتين المقسمتين بالمثال الموضح بالأعلى، سيحقق نموذج العبارة النتائج التالية:

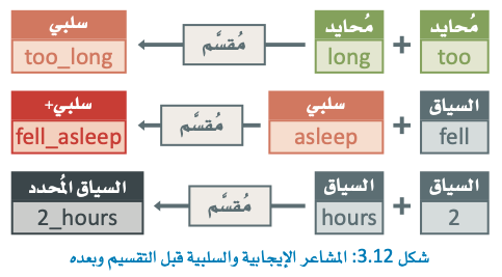
يحدد نموذج العبارة ثلاثة عبارات على النحو التالي:
- Fell_asleep (سقط نائمًا).
- Too_long (طويل جدًا).
- 2-hours (2 – ساعة).
وجميعها تحمل معلومات أكثر من كلماتها المفردة.
- على سبيل المثال، تحمل عبارة too_long (طويل جدًا) مشاعر سلبية واضحة، على الرغم من أن كلمتي too(جدًا) و long (طويل) لا تعبران عن ذلك منفردتين.
- وبالمثل، فعلى الرغم من أن كلمة asleep (نائم) في مراجعة الفيلم تمثل دلالة سلبية، فالعبارة fell_asleep(سقط نائمًا) توصل رسالة أكثر وضوحًا.
- وأخيرًا، تستنبط من 2-hours ( 2- ساعة) سياقًا أكثر تحديدًا من الكلمتين 2 و hours كل على حدة.
تستخدم الدالة التالية إمكانية تحديد العبارات بهذا الشكل لتفسير العبارات في وثيقة معطاة:

يستخدم المقطع البرمجي التالي دالة annotate_phrases() لتفسير كل من تقييمات التدريب والاختبار من مجموعة بيانات IMDb.


استخدام مقياس تكرار المصطلح – تكرار المُستنَد العكسي في البرمجة الاتجاهية للنصوص (Using TF-IDF for Text Vectorization)
تكرار الكلمة في المستند لا يعد دومًا تمثيلاً دقيقًا لأهميتها.
الطريقة المثلى لتمثيل التكرار هي المقياس الشهير لتكرار المصطلح – تكرار المستند العكسي (TF-IDF).
تعريف هام
تكرار المصطلح – تكرار المستند العكسي (Term Frequency Inverse Document Frequency (TF-IDF))
تكرار المصطلح – تكرار المُستنَد العكسي هو طريقة تُستخدَم لتحديد أهمية الرموز في المُستنَد.
يستخدم هذا المقياس صيغة رياضية بسيطة لتحديد أهمية الرموز مثل: الكلمات أو العبارات في المستند بناء على عاملين:
- تكرار الرمز في المستند بقياس عدد مرات ظهوره في المستند مقسومًا على إجمالي عدد الرموز في جميع المستندات.
- تكرار المستند العكسي للرمز، المحسوب بقسمة إجمالي عدد المستندات في مجموعة البيانات على عدد المستندات التي تحتوي على رمز.
العامل الأول يتجنب المبالغة في تقدير أهمية المصطلحات التي تظهر في الوثائق الأطول، بينما العامل الثاني فيستبعد المصطلحات التي تظهر في كثير من المستندات مما يساعد على إثبات حقيقة أن بعض الكلمات هي الأكثر شيوعًا من غيرها.

أداة TfidVectorizer
توفر مكتبة سكليرن (SKlearn) أداة تدعم هذا النوع من البرمجة الاتجاهية لتكرار المصطلح – تكرار المستند العسكي TF-IDF. يمكن استخدام أداة TfidVectorizer لتمثيل عبارة باستخدام المتجهات.

يمكن الآن إدخال أداة التمثيل بالمتجهات في مصنف بايز الساذج لبناء خط أنابيب نموذج تنبؤ جديد وتطبيقه على بيانات اختبار IMDb:

يحقق خط الأنابيب الجديد دقة تصل إلى 88.58% وهو تحسن كبير بالمقارنة مع الدقة السابقة التي وصلت إلى 84.68%، يمكن الآن استخدام النموذج المحسن لإعادة النظر في مثال الاختبار الذي تم تصنيفه بشكل خاطئ بواسطة النموذج الأول:

يتنبأ خط الأنابيب الجديد بشكل صحيح بالقيمة الإيجابية لهذ التقييم، يستخدم المقطع البرمجي التالي مفسر النموذج المحايد المحلي القابل للشرح والتفسير (LIME) لتفسير المنطق وراء هذا التنبؤ:

تؤكد النتائج أن خط الأنابيب الجديد يتبع منطقًا أكثر ذكاءً، فهو يحدد بشكل صحيح المشاعر الايجابية للعبارات مثل beautifully_shot (لقطة جميلة) وsuperb_acting (تمثيل رائع) وvery_good (جيد جدًا) ولا يمكن تضليله باستخدام الكلمات التي جعلت خط الأنابيب الأول يتنبأ بنتائج خاطئة.
يمكن تحسين أداء خط الأنابيب لنموذج التنبؤ بطرائق متعددة:
استبدال مصنف بايز البسيط بطرائق أكثر تطورًا مع ضبط متغيراتها لزيادة احتمالاتها.
استخدام تقنيات البرمجة الاتجاهية البديلة التي لا تستند إلى تكرار الرمز مثل: تضمين الكلمات والنصوص وسيُستعرض ذلك في الرمز التالي.
بإمكانك مراجعة محتوى موضوع “التعلم الموجه” بدايةً من عنوان “تحسين البرمجة الاتجاهية للنصوص” وحتى نهاية الموضوع، من خلال الرابط التالي:
اختبر تحصيلك لمحتوى الموضوع من خلال الرابط التالي:
الواجب الإلكتروني
إلى هنا يكون قد انتهى موضوع “التعلم الموجه“، لا تنسوا مراجعة أهداف التعلُّم أعلى المقال، وانتظرونا في الموضوع القادم!