التعلم غير الموجه | الوحدة الثالثة | الدرس الثاني

التعلم غير الموجه هو عنوان الدرس الثاني من الوحدة الثالثة التي تحمل اسم “معالجة اللغات الطبيعية” في الفصل الدراسي الأول من مقرر “الذكاء الاصطناعي”.
ستتعرف في هذا الموضوع على كيفية استخدام التعلُّم غير الموجَّه لفهم النصوص، وكيفية إنشاء خوارزميات التجميع، وخطوات تطبيق البرمجة الاتّجاهية للنصوص، وتحديد تقنيات تقليص الأبعاد، وكيفية تطبيق التجميع التكتلي ومسافة وارد، بالإضافة إلى شرح البرمجة الاتّجاهية للكلمات باستخدام الشبكات العصبية، وشرح البرمجة الاتّجاهية للجُمل باستخدام التعلُّم العميق.

لذا قم بقراءة أهداف التعلُّم بعناية، ثم أعد قراءتها وتأكَّد من تحصيل كافة محتوياتها بعد انتهائك من دراسة الموضوع.
أهداف التعلُّم
- استخدام التعلُّم غير الموجَّه لفهم النصوص.
- إنشاء خوارزميات التجميع.
- تطبيق البرمجة الاتّجاهية للنصوص.
- تحديد تقنيات تقليص الأبعاد.
- تطبيق التجميع التكتلي.
- تطبيق مسافة وارد.
- شرح البرمجة الاتّجاهية للكلمات باستخدام الشبكات العصبية.
- شرح البرمجة الاتّجاهية للجُمل باستخدام التعلُّم العميق.
هيا لنبدأ!
استخدام التعلُّم غير الموجَّه لفهم النصوص (Using Unsupervised Learning to Understand Text)
هو نوع من تعلم الآلة، يستخدم فيه النموذج بيانات غير معنونة حيث يقدم له مجموعة من الأمثلة التي يتولى البحث فيها عن الأنماط والعلاقات بين البيانات من تلقاء نفسه.
في سياق فهم النص يمكن استخدام التعلم غير الموجه في تحديد الهياكل والأنماط الكامنة ضمن مجموعة بيانات المستندات النصية.

هناك العديد من التقنيات المختلفة التي يمكن استخدامها في التعلم غير الموجه للبيانات النصية، بما في ذلك:
- بيانات التجميع Clustering Algorithm
- تستخدم خوارزميات التجميع لضم المستندات المتشابهة معًا.
- تقنيات تقليص الأبعاد Dimensionally Reduction Techniques
- تستخدم لتقليص أبعاد البيانات وتحديد الخصائص الهامة.
- النماذج التوليدية Generative Models
- تستخدم لتعلم التوزيع الأساسي للبيانات وتوليد نص جديد مشابه لمجموعة البيانات الأصلية.
تعريفات هامة
التعلُّم غير الموجَّه (Unsupervised Learning)
في التعلُّم غير الموجَّه، يُزوَّد النموذج بكميات كبيرة من البيانات غير المُعنوَنة ويتوجب عليه البحث عن الأنماط في البيانات غير المُتراكبة من خلال الملاحظة والتجميع.
تقليص الأبعاد (Dimensionality Reduction)
تقنية تقليص الأبعاد هي إحدى تقنيات تعلُّم الآلة وتحليل البيانات المُستخدَمة لتقليص عدد الخصائص (الأبعاد) في مجموعة البيانات مع الاحتفاظ بأكبر قدر ممكن من المعلومات.
لمعرفة المزيد من المعلومات عن التعلم غير الموجه، قم بالاطّلاع على الرابط التالي:
خوارزميات التجميع Clustering Algorithm
يمكن لخوارزميات التجميع تجميع العملاء المتشابهين استنادًا إلى السلوكيات أو الديموغرافيا، أو سجل المشتريات لأغراض التسويق المستهدف وزيادة معدلات الاحتفاظ بالبيانات.
تقنيات تقليص الأبعاد Dimensionally Reduction Techniques
تستخدم تقنيات تقليص الأبعاد في ضغط الصورة لتقليل عدد وحدات البيكسل فيها، مما يساعد على تقليص حجم البيانات اللازمة لتمثليها مع الحفاظ على خصائصها الرئيسة.
توليد النماذج Generative Models
تستخدم النماذج التوليدية في تطبيقات الكشف عن الاختلاف، حيث تحدد الاختلافات في البيانات بتعلم الأنماط الطبيعية للبيانات باستخدام النموذج التوليدي.
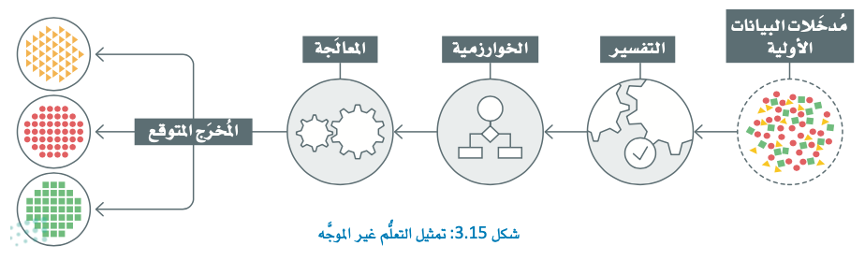
إحدى المزايا الرئيسة لاستخدام التعلم غير الموجه هي أنه يمكن استخدامه للكشف عن الأنماط والعلاقات التي قد لا تبدو واضحة على الفور للمراقب البشري.
ويكون هذا مفيدًا بشكل خاص في فهم مجموعة البيانات الكبيرة المكونة من النصوص غير المتراكبة حيث يكون التحليل اليدوي غير عملي.
في هذه الوحدة، ستستخدم مجموعة بيانات متوافرة للعامة من المقالات الإخبارية من هيئة الإذاعة البريطانية (BBC)بواسطة جرين وكوننجهام لتوضيح بعض التقنيات الرئيسة للتعلم غير الموجه.
تعريف هام
العنقود (Cluster)
العنقود هو مجموعة من الأشياء المتشابهة. وفي تعلُّم الآلة، يشير التجميع (Clustering) إلى عملية تجميع البيانات غير المُعنوَنة في عناقيد متجانسة.

يستخدم المقطع البرمجي التالي لتحميل مجموعة البيانات المنظمة في خمسة مجلدات إخبارية مختلفة تمثل مقالات من أقسام إخبارية هي: الأعمال التجارية، السياسة، الرياضة، التقنية والترفيه. لن تستخدم القيم الخمسة في توجيه أي من الخوارزميات المستخدمة في هذه الوحدة.
بدلاً من ذلك، ستُستخدم فقط لأغراض التصوير والمصادقة يتضمن كل مجلد إخباري مئات الملفات النصية وكل ملف يتضمن محتوى مقالة واحدة محددة.
وقد حملت مجموعة البيانات بالفعل إلى مفكرة جوبيتر (Jupyter Notebook) وستقوم لبنة التعليمات البرمجية بفتح واستخراج كل المستندات والقيم المطلوبة في تركيبتين لبيانات القوائم على التوالي.

تجميع المستندات (Document Clustering)
الآن، بعد تحميل مجموعة البيانات فإن الخطوة التالية هي تجربة عدة طرق غير موجهة ومنها: التجميع الذي يعد الطريقة غير الموجهة الأكثر شهرة في هذا النطاق.
وبالنظر إلى مجموعة المستندات غير المعنونة سيكون الهدف هو تجميع الوثائق المتشابهة معًا، وفي الوقت نفسه الفصل بين الوثائق غير المتشابهة.
تعريف هام
تجميع المُستنَدات (Document Clustering)
تجميع المُستنَدات هو طريقة تُستخدَم لتجميع المُستنَدات النصيّة في عناقيد بناءً على تشابه محتواها.

تحديد عدد العناقيد (Selecting the Number of Clusters)
تحديد العدد الصحيح للعناقيد هو خطوة ضرورية ضمن مهام التجميع، للأسف تعتمد الغالبية العظمى من خوارزميات التجميع على المستخدم في تحديد عدد العناقيد الصحيحة ضمن المدخلات، ربما يكون للعدد تأثيرًا كبيرًا على جودة النتائج وقابليتها للتفسير.
ولكن هناك العديد من المقاييس أو المؤشرات التي يمكن استخدامها لتحديد عدد العناقيد:
- إحدى الطرائق الشائعة هب استخدام مقياس التراص (Compactness) يمكن القيام بذلك عن طريق حساب مجموع المسافات بين النقاط ضمن كل عنقود، وتحديد عدد العناقيد الذي يقلل من هذا المجموع إلى الحد الأدنى.
- هناك طريقة أخرى تتلخص في مقياس الفصل (Separation) بين العناقيد مثل: متوسط المسافة بين النقاط في العناقيد المختلفة، وبناء عليه يتم تحديد عدد العناقيد الذي يرفع من هذا المتوسط.
وبشكل عملي غالبًا ما تتعارض المنهجيات المذكورة بالأعلى مع بعضها من حيث التوصية بأرقام مختلفة، ويمثل هذا تحديًا كبيرًا مشتركًا عند التعامل مع البيانات النصية بشكل خاص، فعادة ما يصعب تمييز تركيبها.
تعريفات هامة
المسافة الإقليدية (Euclidean Distance)
المسافة الإقليدية هي مسافة الخط المستقيم بين نقطتين في فضاء متعدد الأبعاد. وتُحسب بالجذر التربيعي لمجموع مربعات الفروقات بين الأبعاد المناظرة للنقاط. تُستخدَم المسافة الإقليدية في التجميع لقياس التشابه بين نقطتي بيانات.
مسافة جيب التمام (Cosine Distance)
تُستخدَم مسافة جيب التمام لقياس التشابه في جيب التمام بين نقطتي البيانات. فهي تحسب جيب تمام الزاوية بين متَّجَهين يمثلان نقاط البيانات، وتُستخدَم عادةً في تجميع البيانات النصيّة. وتقع قيمة جيب التمام بين -1 و1؛ حيث تشير القيمة -1إلى الاتجاه العكسي، بينما تشير القيمة 1 إلى الاتجاه نفسه.

في التعلم غير الموجه، يشير عدد العناقيد إلى عدد المجموعات أو التصنيفات التي تنقسم إليها البيانات بواسطة الخوارزمية.
يعد تحديد عدد العناقيد الصحيح أمرًا مهمًا لأنه يؤثر على دقة النتائج وقابليتها للتفسير.
إذا كان عدد العناقيد كبيرًا للغاية فإن المجموعات ستكون محددة جدًا وبدون معنى بينما إذا كان عدد العناقيد منخفضًا للغاية فإن المجموعات ستكون ممتدة على نطاق واسع جدًا ولن تستنبط التركيب الأساسي للبيانات.
من الضروري تحقيق التوازن بين توفير عدد كاف من العناقيد لاستنباط أنماط ذات معنى. وألا تكون كثيرة في الوقت نفسه بالقدر الذي يجعل النتائج معقدة للغاية وغير مفهومة.
تعريف هام
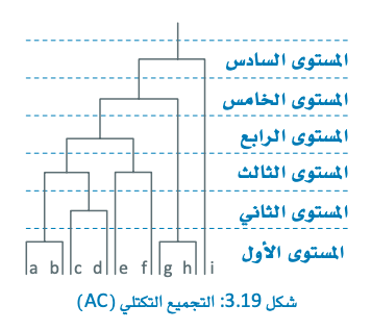
التجميع الهرمي (Hierarchical Clustering)
التجميع الهرمي هو خوارزمية التجميع المُستخدَمة لتجميع البيانات في عناقيد بناءً على التشابه. في التجميع الهرمي، تُنظّم نقاط البيانات في تركيب يشبه الشجرة، حيث تكون كل عُقدة بمثابة عنقود، وتكون العُقدة الأم هي نقطة التقاء العُقد المتفرعة منها.
يستخدم المقطع البرمجي التالي لاستيراد مكتبات محددة تستخدم في التجميع الهرمي من بدايته وحتى نهايته.

بإمكانك مراجعة محتوى موضوع “التعلم غير الموجه” من بدايته وحتى نهاية هذا القسم، من خلال الرابط التالي:
البرمجة الاتجاهية للنصوص (Text Vectorization)
تتطلب العديد من طرائق التعلم غير الموجه تمثيل النص الأولي بالمتجهات في تنسيق رقمي، كما تم عرضه في الوحدة السابقة.
ويستخدم المقطع البرمجي التالي أداة TfidVectorize التي استخدمت في الدرس السابق لهذا الغرض:

الآن تحولت بيانات النص إلى تنسيق رقمي متباعد كما استخدمت في الدرس السابق.
يستخدم المقطع البرمجي التالي أداة TSENVisualizer من مكتبة Yellowbrick لإسقاط وتصوير النصوص الممثلة بالمتجهات في فضاء ثنائي الأبعاد:

تقليص الأبعاد Dimensionally Reduction
يكون تقليص الأبعاد مفيدًا في العديد من التطبيقات مثل:
- تصوير البيانات عالية الأداء
- من الصعب تصوير البيانات في فضاء عالي الأبعاد، ولذلك تقلص الأبعاد ليسهل تصوير البيانات وفهمها في هذه الحالة.
- تبسيط النموذج
- النموذج ذو الأبعاد يكون أبسط وأسهل فهمًا ويستغرق وقتًا أقل في عملية التدريب.
- تحسين أداء النموذج
- يساعد تقليص الأبعاد في التخلص من التشويش وتكرار البيانات مما يحسن أداء النموذج.
تعريف هام
تضمين المجاور العشوائي الموزع على شكل T (t-Distributed Stochastic Neighbor Embedding (T-SNE))
خوارزمية تضمين المجاور العشوائي الموزَّع على شكل T (T-SNE) هي خوارزمية تعلُّم الآلة غير الموجَّه المُستخدَمة لتقليص الأبعاد.
إحدى الخصائص الرئيسة لتقنية تضمين المجاور العشوائي الموزع على شكل T (T-SNE) هي محاولة الحفاظ على التركيب المجلي للبيانات قدر الإمكان، حتى تتقارب نقاط البيانات في التمثيل منخفض الأبعاد.
يتحقق ذلك بتقليص التباعد بين النقطتين المحتملتين:
- توزيع البيانات عالية الأبعاد.
- توزيع البيانات منخفضة الأبعاد.
مجموعة بيانات هيئة الإذاعة البريطانية الممثلة بالمتجهات تصنف بالتأكيد كبيانات عالية الأبعاد، لأنها تتضمن بُعدًا مستقلاً أي عمودًا (Columns) لكل كلمة فريدة تظهر في البيانات يحسب العدد الإجمالي للأبعاد كما يلي:

يستخدم المقطع البرمجي التالي لإسقاط 5.867 بُعدًا في محورين فقط وهما محوري x و y في الرسم البياني.
يستخدم المقطع البرمجي التالي لتصميم مخطط الانتشار حي يمثل كل لون أحد الأقسام الإخبارية الخمسة.

يستخدم هذا التصور قيمة ground-truth (بيانات الحقيقة المعتمدة) من القسم الإخباري (News Section) في كل مستند للكشف عن انتشار كل قيمة في إسقاط فضاء البرمجة الاتجاهية ثنائي الأبعاد.
يوضح الشكل على أنه على الرغم من ظهور بعض الشوائب في فراغات محددة من فضاء البيانات، إلا أن الأقسام الإخبارية الخمسة منفصلة بشكل جيد وسنستعرض لاحقًا البرمجة الاتجاهية المحسنة للحد من هذه الشوائب.
التجميع التكتلي Agglomerative Clustering
هو الطريقة الأكثر انتشارًا وفعالية في هذا الفضاء، فمن خلالها يمكن التغلب على هذا التحدي بتوفير طريقة واضحة لتحديد العدد المناسب من العناقيد.
يستند التجميع الكلي إلى منهجية التصميم من أسفل إلى أعلى حيث تبدأ بحساب المسافة بين كل أزواج نقاط البيانات ثم اختيار النقطتين الأقرب ودمجهما في عنقود واحد تتكرر هذه العملية حتى تدمج كل نقاط البيانات في عنقود واحد أو حتى الوصول إلى العدد المطلوب من العناقيد.
دالة Linkage()
تنفذ لغو بايثون التجميع التكتلي (AC) باستخدام دالة linkage()
يجب توفير متغيرين لدالة linkage():
- البيانات النصية الممثلة بالمتجهات ويمكن استخدام دالة toarray() لتحويل البيانات إلى تنسيق كثيف يمكن لهذه الدالة أن تتعامل معه.
- مقياس المسافة الذي يجب استخدامه لتحديد العناقيد التي ستُدمج أثناء عملية التجميع التكتلي، تتوفر عدة خيارات من مقاييس المسافة للاختيار من بينهما وفقًا لمتطلبات وتفضيلات المستخدم ومنها:
- المسافة الإقليدية Euclidian
- مسافة مانهاتان Manhattan
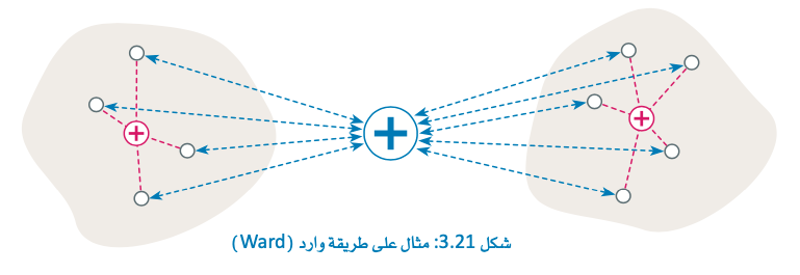
ولكن في هذا المشروع ستستخدم طريقة وارد (ward) القياسية.
يستخدم المقطع البرمجي التالي دالة linkage() من الأداة الهرمية (Hierarchy) الوارد بالأعلى لتطبيق هذه العملية على هيئة الإذاعة البريطانية الممثلة بالمتجهات:

مسافة وارد Ward Distances
يستخدم المثال السابق طريقة وارد ward القياسية لقياس المسافة للمتغير الثاني.
تستند مسافة وارد ward إلى مفهوم التباين داخل العنقود، وهو مجموع المسافات بين النقاط في العنقود في كل تكرار.
تقيم الطريقة كل عملية دمج ممكنة بحساب التباين داخل المنقود قبل عملية الدمج، وبعدها، ثم تبدأ عملية الدمج التي تحقق أقل ارتفاع في التباين.
أظهرت مسافة وارد ward نتائج جيدة في معالجة البيانات النصية بالرغم من وجود العديد من الخيارات الأخرى.
الرسم الشجري في الشكل أعلاه يعرض طريقة واضحة لتحديد عدد العناقيد في هذا المثال، تقترح المكتبة استخدام 7 عناقيد مع تمييز كل عنقود بلون مختلف قد يتبنى المستخدم هذا المقترح أو يستخدم الرسم الشجري لاختيار رقم مختلف.
على سبيل المثال، دمج اللونين الأخضر والأزرق في آخر خطوة مع مجموعة العناقيد لكل الألوان الأخرى، وهكذا سيؤدي إلى اختبار 6 عناقيد إلى دمج اللونين الأرجواني والبرتقالي بينما اختيار 5 عناقيد سيؤدي إلى دمج اللونين الأزرق والأخضر.
تعريف هام
الرسم الشجري (Dendrogram)
الرسم الشجري هو رسم تخطيطي تفرعي يوضِّح العلاقة الهرمية بين البيانات، ويأتي عادةً في صورة أحد مُخرَجات التجميع الهرمي.
يتبنى المقطع البرمجي التالي مقترحات الأداة ويستخدم أداة التجميع التكتلي من مكتبة سكليرن (SKlearn) لتقسيم المخطط الشجري بعد إنشاء العناقيد السبع:

لاحظ أن قيمة ground-truth (بيانات الحقيقة المعتمدة) من القسم الإخباري (News Section) في كل مستند لم يستخدم على الإطلاق في هذه العملية وبدلاً من ذلك عولجت عملية التجميع استنادًا إلى نص محتوى كل وثيقة على حدة إن قيم بيانات الحقيقة المعتمدة مفيدة في التطبيق العملي فهي تتيح التحقق من صحة نتائج التجميع وقيم بيانات الحقيقة المعتمدة الحالية موجودة في قائمة bbc_labels قيم هيئة الإذاعة البريطانية.
يستخدم المقطع البرمجي التالي قيم بيانات الحقيقة المعتمدة وثلاثة دوال مختلفة لتسجيل النقاط من مكتبة سكليرن (SKlearn) لتقييم جودة تجميع البيانات:
- تكون مؤشر قيمة التجانس (Homogeneity Score) بين 0 و1
يمكن زيادة هذه القيم عندما تكون كل النقاط في كل عنقود لها قيمة بيانات الحقيقة المعتمدة وبالمثل يحتوي كل عنقود على نقاط البيانات وحيدة التصنيف.
- تكون قيمة مؤشر رائد المعدل (Adjusted Rand Score) بين 0.5 و 1.0
يمكن زيادة هذه القيم عندما تقع كل نقاط البيانات ذات القيم نفسها في العنقود نفسه وكل نقاط البيانات ذات القيم المختلفة في عناقيد مختلفة.
- تكون قيمة مؤشر الاكتمال (Completeness Score) بين 0 و1 و
يمكن زيادة هذه القيمة بتعيين كل نقاط البيانات من تصنيف محدد في العنقود نفسه.

على الرغم من أن نتائج المؤشر تظهر أن التجميع التكتلي باستخدام البرمجة الاتجاهية لتكرار المصطلح -تكرار المستند العكسي (TF-IDF) تحقق نتائج معقولة إلا أنه لا يزال بالإمكان تحسين دقة عملية التجميع، سيوضح القسم التالي كيف يمكن أن نحقق نتائج مبهرة باستخدام تقنيات البرمجة الاتجاهية المستندة على الشبكات العصبية.
البرمجة الاتجاهية للكلمات باستخدام الشبكات العصبية (Word Vectorization with Neural Networks)
البرمجة الاتجاهية لتكرار المصطلح تكرار المستند العسكي (TF-IDF) تستند إلى حساب تكرار الكلمات ومعالجتها غبر المستندات في مجموعة البيانات. بالرغم من أن هذا يحقق نتائج جيدة، إلا أن القيود الكبيرة تعيق الطرائق المستندة إلى التكرار فهي تتجاهل تمامًا العلاقة الدلالية بين الكلمات.
على سبيل المثال، بالرغم من أن كلمتي trip (نزهة) و journey (رحلة) مترادفتان إلا أن البرمجة الاتجاهية المستندة إلى التكرار ستتعامل معهما باعتبارهما كلمتان منفصلتان تمامًا ولهما خصائصهما المستقلة.
وبالمثل، بالرغم من أن كلمتي apple (تفاحة) و fruit (فاكهة) مترابطتان دلاليًا لأن التفاح نوع من الفاكهة إلا أن ذلك لا يؤخذ بعين الاعتبار أيضًا.
تؤثر هذه القيود كثيرًا على التطبيقات التي تستخدم هذا النوع من البرمجة الاتجاهية فكر في الجملتين التاليتين:
- Have a very high fever, So I have to visit a doctor (لدي حمى شديدة، ويجب زيارة الطبيب).
- My body temperature has risen significantly, so I need to see a healthcare professional (ارتفعت درجة حرارة جسمي كثيرًا، ويجب علي زيارة أخصائي الرعاية الصحية).
بالرغم من أن الجملتين تصفان الحالة نفسها إلا أنهما لا تتشاركان أي كلمات دلالية، ولذلك ستفشل خوارزميات التجميع المستندة إلى تكرار المصطلح تكرار المستند العكسي TF-IDF أو أي برمجة اتجاهية (تستند إلى التكرار) في رؤية التشابه بين الكلمات، ومن المحتمل ألا تضعها في نفس العنقود.
نموذج الكلمة إلى المتجه Word2Vec
يمكن معالجة هذه القيود بالطرائق التي تأخذ بعين الاعتبار التشابه الدلالي بين الكلمات.
إحدى الطرق الشهيرة المتبعة في هذا الصدد هي نموذج الكلمة إلى المتجه Word2Vec التي تستخدم بنية تستند إلى الشبكات العصبية.
يستند نموذج الكلمة إلى المتجه Word2Vec إلى فكرة أن الكلمات المتشابهة دلاليًا تحاط بكلمات مماثلة في السياق نفسه.
لذلك، نجد أن الشبكات العصبية تستخدم التضمين الخفي لكل كلمة للتنبؤ بالسياق، مع ضرورة إنشاء الروابط بين الكلمات والتضمينات الشبيهة عمليًا، يخضع نموذج الكلمة إلى المتجه Word2Vec للتدريب المسبق على ملايين المستندات لتعلم التضمين عالي الدقة للكلمات.
تعريفات هامة
الكلمات المُستبعَدة (Stopwords)
الكلمات المُستبعَدة هي كلمات شائعة غي اللغات تُستبعد عادةً أثناء المعالجة المُسبَقة للنصوص ضمن مهام معالجة اللغات الطبيعية (NPL) مثل البرمجة الاتّجاهية للكلمات. هذه الكلمات تشمل أدوات التعريف، وحروف الجر، والكلمات التي لا تكون مفيدة لتحديد معنى النصّ، أو سياقه.
التضمين (Embedding)
التضمين يُعبِّر عن الكلمات أو الرموز في فضاء المتَّجَه المستمر حيث ترتبط الكلمات المتشابهة دلاليًا مع النقاط القريبة.
يمكن تحميل النماذج المدربة مسبقًا واستخدامها في التطبيقات المستندة إلى النصوص يستخدم المقطع البرمجي التالي مكتبة (Gensim) لتحميل نموذج شهير مدرب مسبقًا على مجموعة كبيرة جدًا من أخبار قوقل (Google News):

الأبعاد العشرة للتضمين العددي لكلمة fox (ثعلب) موضح بالأسفل:

يستخدم النموذج تضمينات الكلمات لتقييم درجة التشابه، فكر في المثال التالي حيث تظهر المقارنة بين كلمتي car (السيارة) والكلمات الأخرى درجة التشابه من خلال تناقض قيم التشابه، علمًا بأن قيم التشابه تقع دومًا بين 0 و1.

يمكن استخدام المقطع البرمجي التالي للعثور على الكلمات الخمسة المشابهة لإحدى الكلمات:

بإمكانك مراجعة محتوى موضوع “التعلم غير الموجه” بدايةً من عنوان “البرمجة الاتجاهية للنصوص” وحتى هذه النقطة، من خلال الرابط التالي:
يمكن استخدام التصوير في التحقق من صحة تضمينات هذا النموذج المدرب مسبقًا، ويمكن تحقيق ذلك عبر:
- تحديد نماذج الكلمات من مجموعة بيانات هيئة الإذاعة البريطانية.
- استخدام تضمين المجاور العشوائي الموزع على شكل T (T-SNE) لتخفيض التضمين ذي 300 بعد لكل كلمة إلى نقطة ثنائية الأبعاد.
- تصوير النقاط في مخطط الانتشار في الفضاء ثنائي الأبعاد.

تستخدم الدالة الآتية لاحقًا لتحديد عينة من الكلمات التمثيلية من مجموعة بيانات هيئة الإذاعة البريطانية، يحدد المقطع البرمجي الكلمات الخمسين الأكثر تكرارًا على وجه التحديد من الأقسام الإخبارية الخمسة لهيئة الإذاعة البريطانية مع استثناء الكلمات المستبعدة (Stopwords) وهي الكلمات الإنجليزية الشائعة جدًا والكلمات التي لم تُضمن في نموذج الكلمة إلى المتجه (Word2Vec) المدرب مسبقًا.

وأخيرًا ستستخدم طريقة تضمين المجاور العشوائي الموزع على شكل T (T-SNE) لتخفيض التضمينات ذات ال 300 بعد للكلمات في العينة ضمن النقاط ثنائية الأبعاد بعدها تمثل النقاط في مخطط انتشار بسيط.

يثبت المخطط أن تضمينات نموذج الكلمة إلى المتجه (Word2Vec) تستنبط الارتباطات الدلالية بين الكلمات كما يتضح من مجموعات الكلمات الواضحة مثل:
- economic / economy (الاقتصاد)، business (الأعمال)، financial (المالية)، sales (المبيعات)، firm / firms (الشركات)، bank (البنك).
- Internet (الإنترنت)، mobile (الهاتف)، phones (الهواتف)، phone (الهاتف)، broadband(النطاق العريض)، online (متصل)، digital (رقمي).
- Actor (ممثل)، actress (ممثلة)، film (فيلم)، comedy (كوميدي)، films (أفلام)، festival(مهرجان)، band (فرقة)، movie (فيلم).
- game (لعبة)، team (فريق)، match (مباراة)، players (لاعبون)، coach (مدرب)، injury(إصابة)، club (نادي)، rugby (الرجبي).
البرمجة الاتجاهية للجُمل باستخدام التعلُّم العميق (Sentence Vectorization with Deep Learning)
على الرغم من إمكانية استخدام نموذج الكلمة إلى المتجه Word2Vec في نمذجة الكلمات الفردية، يتطلب التجميع للبرمجة الاتجاهية للنص بأكمله.
إحدى الطرائق الأكثر شهرة لتحقيق ذلك هي تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT) المستندة إلى منهجية التعلم العميق.
- تمثيلات الترميز ثنائية الاتجاه من المحولات Bidirectional Encoder Representation from Transformers (BERT)
هي نموذج تمثيل لغوي قوي طورته شركة قوقل، ويعد التدريب المسبق والضبط الدقيق عاملان رئيسان وراء قدرته على تطبيق نقل التعلم، أي القدرة على الاحتفاظ بالمعلومات حول مشكلة ما والاستفادة منها في حل مشكلة أخرى.
يتم التدريب المسبق عبر تغذية النموذج بكمية هائلة من البيانات غير المعنونة لعدة مهام مثل: التنبؤ اللغوي المقنع (إخفاء الكلمات العشوائية في مدخلات النصوص والمهمة هي التنبؤ بهذه الكلمات).
يُهيئ نموذج تمثيلات الترميز ثنائية الاتجاه من المحولات BERT المتغيرات المدربة مسبقًا للضبط الدقيق، كما تٌستخدم مجموعة البيانات المعنونة من المهام النهائية لضبط دقة عمل النموذج، ويكون لكل مهمة نهائية نماذج دقيقة منفصلة برغم أنها مهيئة بالمتغيرات المدربة نفسها مسبقًا.
على سبيل المثال، تختلف عملية الضبط الدقيق لنموذج تحليل المشاعر عن نموذج الإجابة على الأسئلة ومن المهم معرفة أن الفروقات في بنية النماذج تصبح ضئيلة أو منعدمة بعد خطوة ضبط الدقة.
- تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات SBERT
(SBERT) هي الإصدار المعدل من (BERT).
تُدرب BERT مثل نموذج Word2Vec للتنبؤ بالكلمات بناء على سياق الجمل الواردة بها.
من ناحية أخرى، تُدرب SBERT للتنبؤ بما إذا كانت جملتان متشابهتان دلاليًا.
تُستخدم (SBERT) لإنشاء تضمينات لأجزاء النصوص الأطول من الجمل مثل الفقرات أو النصوص القصيرة أو المقالات في مجموعة بيانات هيئة الإذاعة البريطانية في محل الدراسة في هذه الوحدة بالرغم من أن النماذج الثلاث تستند جميعها إلى الشبكات العصبية إلا أن BERT وSBERT تتبعان بنية مختلفة بشكل كبير وأكثر تعقيدًا من نموذج الكلمة إلى المتجه Word2Vec.
- مكتبة الجمل والمحولات Sentence_transformers Library
تطبيق مكتبة الجمل والمحولات الوظائف الكامنة لنموذج SBERT تأتي المكتبة بالعديد من النماذج (SBERT)المدربة مسبقًا كل منها مُدرب على مجموعة بيانات مختلفة ولتحقيق أهداف مختلفة.
يعمل المقطع البرمجي التالي على تحميل أحد النماذج العامة الشهيرة المدربة مسبقًا، ويستخدمها لإنشاء تضمينات للمستندات في مجموعة بيانات هيئة الإذاعة البريطانية:

لقد استخدمت في وقت سابق في هذه الوحدة أداة تضمين المجاور العشوائي الموزع على شكل T والتي هي (TSNE Visualizer) لتصوير المستندات الممثلة بالمتجهات المنتجة باستخدام أداة تكرار المصطلح تكرار المستند العكسي (TF-IDF) يمكن الآن استخدامها للتضمينات المنتجة بواسطة تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT):

يوضح الشكل أن تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT) تؤدي إلى فصل أكثر وضوحًا للأقسام الإخبارية المختلفة مع عدد أقل من الشوائب من تكرار المصطلح تكرار المستند العكسي (TD-IDF).
الخطوة التالية هي استخدام التضمينات لتدريب خوارزمية التجميع التكتلي:

كما هو موضح بالشكل أعلاه، فإن أداة الرسم الشجري تشير إلى 4 عناقيد، كل واحد منها مميز بلون مختلف.
يستخدم المقطع البرمجي التالي هذا المقترح لحساب العناقيد وحساب مقاييس التقييم:

إذا كانت البيانات قد تم إعادة تجميعها باستخدام العدد الصحيح من 5 عناقيد، فالعنقود الأصفر المحدد بالشكل أعلاه سينقسم إلى اثنين وستكون النتائج على النحو التالي:

تُظهر النتائج ان استخدام تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT) في البرمجة الاتجاهية للنصوص ينتج عنه نتائج تجميع محسنة بالمقارنة مع تكرار المصطلح تكرار المستند العكسي (TF-IDF) (القيمة الصحيحة) و4 عناقيد لتمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT).
فإن المقاييس الثلاثة لتمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT) لا تزال هي الأعلى بفارق كبير ثم تزداد الفجوة إذا كان العدد 5 لكل من الطريقتين.
وهذا يعد دليلًا على إمكانات الشبكات العصبية التي تسمج لها بنيتها المتطورة بفهم الأنماط الدلالية المعقدة في البيانات النصية.
بإمكانك مراجعة محتوى موضوع “التعلم غير الموجه” بدايةً من عنوان “استخدام التصوير في التحقق من صحة تضمينات النموذج” وحتى نهاية الموضوع، من خلال الرابط التالي:
اختبر تحصيلك لمحتوى الموضوع من خلال الرابط التالي:
الواجب الإلكتروني
إلى هنا يكون قد انتهى موضوع “التعلم غير الموجه“، لا تنسوا مراجعة أهداف التعلُّم أعلى المقال، وانتظرونا في الموضوع القادم!