توليد النص | الوحدة الثالثة | الدرس الثالث

توليد النص هو عنوان الدرس الثالث من الوحدة الثالثة التي تحمل اسم “معالجة اللغات الطبيعية” في الفصل الدراسي الأول من مقرر “الذكاء الاصطناعي”.
ستتعرف في هذا الموضوع على مفهوم معالجة اللغات الطبيعية، وتحديد تأثير توليد اللغات الطبيعية، والتمييز بين أنواع توليد اللغات الطبيعية، واستخدام توليد اللغات الطبيعية المبني على القوالب، ومعرفة وُسوم أقسام الكلام، وتحليل بناء الجُمل، واستخدام توليد اللغات الطبيعية المبني على الاختيار، واستخدام توليد اللغات الطبيعية المبني على القواعد، وكيفية إنشاء روبوتات الدردشة، بالإضافة إلى استخدام تعلُّم الآلة لتوليد نصّ واقعي.

لذا قم بقراءة أهداف التعلُّم بعناية، ثم أعد قراءتها وتأكَّد من تحصيل كافة محتوياتها بعد انتهائك من دراسة الموضوع.
أهداف التعلُّم
- تحديد تأثير توليد اللغات الطبيعية.
- التمييز بين أنواع توليد اللغات الطبيعية.
- استخدام توليد اللغات الطبيعية المبني على القوالب.
- معرفة وسوم أقسام الكلام.
- تحليل بناء الجُمل.
- استخدام توليد اللغات الطبيعية المبني على الاختيار.
- استخدام توليد اللغات الطبيعية المبني على القواعد لإنشاء روبوت الدردشة.
- استخدام تعلُّم الآلة لتوليد نص واقعي.
هيا لنبدأ!
توليد اللغات الطبيعية (Natural Language Generation (NLG))
توليد اللغات الطبيعية (NLG) هو أحد فروع معالجة اللغات الطبيعية (NLP) التي تُركز على توليد النصوص البشرية باستخدام خوارزميات الحاسب.

الهدف: توليد للغات المكتوبة أو المنطوقة بصورة طبيعية ومفهومة للبشر دون الحاجة إلى تدخل بشري.
توجد العديد من المنهجيات المختلفة لتوليد اللغات الطبيعية مثل:
- المنهجيات المستندة إلى القوالب.
- المنهجيات المستندة إلى القواعد.
- المنهجيات المستندة إلى تعلم الآلة.

تعريفات هامة
معالجة اللغات الطبيعية (Natural Language Processing – NLP)
معالجة اللغات الطبيعية (NLP) هو أحد فروع الذكاء الاصطناعي الذي يمنح أجهزة الحاسب القدرة على محاكاة اللغات البشرية الطبيعية.
توليد اللغات الطبيعية (Natural Language Generation – NLG)
توليد اللغات الطبيعية (NLG) هي عملية توليد النصوص البشرية باستخدام الذكاء الاصطناعي (AI).
لمعرفة المزيد من المعلومات عن معالجة اللغات الطبيعية (NLP)، قم بالاطّلاع على الروابط التالية:
معالجة اللغة الطبيعية – ويكيبيديا
تأثير توليد اللغات الطبيعية

هناك أربع أنواع من توليد اللغات الطبيعية NLP:
- توليد اللغات الطبيعية المبني على القوالب Template-Based NLG
يتضمن استخدام قوالب محددة مسبقًا تحدد بنية ومحتوى النص المتولد.
تُزود هذه القوالب بمعلومات محددة لتوليد النص النهائي، تعد هذه المنهجية بسيطة نسبيًا وتحقق فعالية في توليد النصوص للمهام المحددة والمعرفة جيدًا.
من ناحية أخرى، قد تواجه صعوبة مع المهام المفتوحة أو المهام التي تتطلب درجة عالية من التباين في النص المولد.
على سبيل المثال، قالب تقرير حالة الطقس ربما يبدو كما يلي:
Today in [city]. It is [temperature] degree. With [Weather condition]
(اليوم في (المدينة). درجة الحرارة هي (درجة الحرارة) مئوية و(حالة الطقس).).
- تضمين اللغات الطبيعية المبنية على الاختيار Selection-Based NLG
يتضمن تحديد مجموعة فرعية من الجمل أو الفقرات لإنشاء ملخص للنص الأصلي الأكبر حجمًا.
بالرغم من أن هذه المنهجية لا تولد نصوصًا جديدة، إلا أنها مطبقة عمليًا على نطاق واسع وذلك لأنها تأخذ العينات من مجموعة من الجمل المكتوبة بواسطة البشر.
يمكن الحد من خطورة توليد النصوص غير المتنبئ بها أو الضعيفة على سبيل المثال، مولد تقرير الطقس المبني على الاختيار قد يضم قاعدة بيانات من العبارات مثل:
- It is not outside (الطقس حار بالخارج).
- The temperature is rising (درجة الحرارة ترتفع).
- Except Sunny Skies (تنبؤات بطقس مشمس).
- توليد اللغات الطبيعية المبني على القواعد Rule-Based NLG
يستخدم مجموعة من القواعد المحددة مسبقًا لتوليد النص، قد تحدد هذه القواعد طريقة تجميع الكلمات والعبارات لتشكيل الجمل أو كيفية اختيار الكلمات وفقًا للسياق المستخدمة فيه.
عادة تُستخدم هذه القواعد لتصميم روبوت الدردشة لخدمة العملاء، قد يكون من السهل تطبيق الأنظمة المبنية على القواعد، وفي بعض الأحيان قد تتسم بالجمود ولا تولد مخرجات تبدو طبيعية.
- توليد اللغات الطبيعية المبني على تعلم الآلة Machine Learning-Based NLG
يتضمن تدريب نموذج تعلم الآلة على مجموعة كبيرة من بيانات النصوص البشرية، يتعلم أنماط النص وبنيته، ومن ثم يمكنه توليد النص الجديد الذي يشبه النص البشري في الأسلوب والمحتوى.
قد تكون المنهجية أكثر فعالية في المهام التي تتطلب درجة عالية من التباين في النص المولد.
قد تتطلب المنهجية مجموعات أكبر من بيانات التدريب والموارد الحسابية.
استخدام توليد اللغات الطبيعية المبني على القوالب (Using Template-Based NLG)
توليد اللغات الطبيعية المبني على القوالب بسيط نسبيًا وقد يكون فعالاً في النصوص للمهام المحددة والمعرفة مثل إنشاء التقارير أو توصيف البيانات.
إحدى مميزات توليد اللغات الطبيعية المبني على القوالب هو سهولة التطبيق والصيانة.
يُصمم الأشخاص القوالب دون الحاجة إلى خوارزميات تعلم الآلة المعقدة أو مجموعات كبيرة من بيانات التدريب. وهذا يجعل توليد اللغات الطبيعية المبني على القوالب هو الخيار المناسب للمهام اليت تكون ذات بنية ومحتوى نص محددين، دون الحاجة إلى إجراء تغييرات كبيرة.
تستند قوالب اللغات الطبيعية (NLG) إلى أي بنية لغوية محددة مسبقًا.
إحدى الممارسات الشائعة هي إنشاء القوالب التي تتطلب كلمات بوسوم محددة كجزء من الكلام لإدراجها في الفراغات المحددة ضمن الجملة.
- وسوم أقسام الكلام Part of Speech (POS)
تُعرف كذلك باسم وسوم POS هي قيم تخصص للكلمات في النص للإشارة إلى البناء النحوي للكلمات أو جزء الكلام في الجملة.
على سبيل المثال، قد تكون الكلمة اسمًا أو فعلاً أو صفة أو ظرفًا، وتُستخدم وسوم أقسام الكلام في معالجة اللغات الطبيعية (NLP) لتحليل بنية النص وفهم معناه.

- تحليل بناء الجمل Syntax Analysis
يُستخدم تحليل بناء الجمل عادة إلى جانب وسوم أقسام الكلام (POS) في توليد اللغات الطبيعية المبني على القوالب لضمان قدرة القوالب على توليد النصوص الواقعية.
يتضمن تحليل بناء الجمل التعرف على أجزاء الكلام في الجمل والعلاقات بينهما لتحديد البناء النحوي للجملة تتضمن الجملة أنواعًا مختلفة من عناصر بناء الجملة مثل:
- الفعل (Predicate)
هو قسم الجملة الذي يحتوي على الفعل وهو عادة يعبر عما يقوم به الفاعل أو عما يحدث.
- الفاعل (Subject)
هو قسم الجملة الذي يُنفذ الفعل.
- المفعول به (Direct Object)
هو اسم أو ضمير يشير إلى الشخص أو الشيء الذي يتأثر مباشرة بالفعل.
يستخدم المقطع البرمجي التالي مكتبة ووندروودز (Wanderwords) التي تتبع منهجية بناء الجمل لعرض بعض الأمثلة على توليد اللغات الطبيعية المبني على القوالب.

توضح الأمثلة بالأعلى أنه، بينما يُستخدم اللغات الطبيعية المبني على القوالب على توليد الجمل وفق بنية محددة ومعتمدة مسبقًا، إلا أن هذه الجمل قد لا تكون ذات مغزى عملي. وعلى الرغم من امكانية تحسين دقة النتائج إلى حد كبير بتحديد قوالب متطورة ووضع المزيد من القيود على استخدام المفردات. إلا أن هذه المنهجية غير عملية لتوليد النصوص الواقعية على نطاق واسع.
فبدلاً من إنشاء القوالب المحددة مسبقًا، تستخدم المنهجية الأخرى لتوليد اللغات الطبيعية القائمة على القوالب البنية والمفردات نفسها المكونة لأي جملة حقيقية كقالب ديناميكي متغير تسمى دالة paraphrase() هذه المنهجية.
دالة Paraphrase()
تقسم الدالة في البداية النص المكون من فقرة إلى مجموعة من الجمل، ثم تحاول استبدال كل كلمة في الجملة بكلمة أخرى متشابهة دلاليًا.
يقيم التشابه الدلالي بواسطة نموذج الكلمة إلى المتجه (Word2Vec) الذي درسته في الدرس السابق، قد يُوصي نموذج الكلمة إلى المتجه (Word2Vec) باستبدال الكلمة في الجملة بكلمة أخرى مشابهة لها، مثل استبدال apple (تفاحة) ب apples (تفاح) ولتجنب مثل هذه الحالات تستخدم مكتبة fuzzywuzzy الشهيرة لتقييم تشابه المفردات بين الكلمة الأصلية والكلمة البديلة.
الدالة نفسها موضحة بالشرائح القادمة:


يستخدم المقطع البرمجي التالي لاستيراد كل الأدوات اللازمة لدعم دالة paraphrase() وفي المربع الأبيض أدناه، تحصل على مخرج طريقة إعادة الصياغة (Paraphrase) للنص المسند إلى متغير Text:

كما في المنهجيات الأخرى المستندة إلى القوالب، يمكن تحسين النتائج بإضافة المزيد من القيود لتصحيح بعض البدائل على الأقل وضوحًا والمذكورة في الأعلى ومع ذلك، يوضح المثال أعلاه أنه يمكن باستخدام هذه الدالة البسيطة توليد نصوص واقعية.
بإمكانك مراجعة محتوى موضوع “توليد النص” من بدايته وحتى نهاية هذا القسم، من خلال الرابط التالي:
استخدام توليد اللغات الطبيعية المبني على الاختيار (Using Selection-Based NLG)
هذه المنهجية تجسد استخدام ومزايا توليد اللغات الطبيعية المبني على الاختيار ويستند إلى لبنتين رئيسيتين:
- نموذج الكلمة إلى المتجه (Word2Vec) المستخدم لتحديد أزواج الكلمات المتشابهة دلاليًا.
- مكتبة NetworkKx الشهيرة ضمن لغة بايثون المستخدمة لإنشاء ومعالجة أنواع مختلفة من بيانات الشبكة.
النص المدخل الذي سيستخدم في هذا الفصل هو مقالة إخبارية نُشرت بعد المباراة النهائية لكأس العالم 2022:

في البداية يرمز النص باستخدام مكتبة re والتعبير النمطي نفسه المستخدم في الوحدات السابقة:

مكتبة Networkx
يمكن الآن نمذجة مفردات المستند في مخطط موزون (Weighted Graph).
توفر مكتبة Networkx في لغة البايثون مجموعة واسعة من الأدوات لإنشاء وتحليل مخططات في توليد اللغات الطبيعية المبني على الاختيار.
يساعد تمثيل مفردات الوثيقة قي مخطط موزون في تحديد العلاقات بين الكلمات وتسهيل اختيار العبارات والجمل ذات الصلة في المخطط الموزون.
تمثل كل عقدة كلمة أو مفهومها، وتمثل الحواف بين العقد أو العلاقات بين هذه المفاهيم تعبر الأوزان على الحواف عن قوة هذه العلاقات، مما يسمح لنظام توليد اللغات الطبيعية بتحديد المفاهيم الأقوى ارتباطًا.
عند توليد النصوص يستخدم المخطط الموزون للبحث عن العبارات والجمل استندًا إلى العلاقات بين الكلمات.
على سبيل المثال، قد يستخدم النظام المخطط للبحث عن الكلمات والعبارات الأكثر ارتباطًا لوصف كيان محدد ثم استخدام هذه الكلمات لتحديد الجهة الأكثر ملاءمة من قاعدة بيانات النظام.

دالة Buid_graph()
تستخدم دالة Buid_graph() مكتبة Networkx لإنشاء مخطط يتضمن:
- عقدة واحدة لكل كلمة ضمن مفردات محددة.
- حافة بين كل كلمتين. الوزن على الحافة يساوي التشابه الدلالي بين الكلمات المحسوب بواسطة أداة Doc2Vecوهي أداة معالجة اللغات الطبيعية المخصصة لتمثيل النص كمتجه وهي تعميم لمنهجية نموذج الكلمة إلى المتجه Word2Vec.
ترسم الدالة مخططًا ذا عقدة واحدة لكل كلمة في المفردات المحددة، توجد كذلك حافة بين عقدتين إذا كان تشابه نموذج الكملة إلى المتجه (Word2Vec) أكبر من الحد المُعطى.

وبالنظر إلى المخطط المبني على الكلمة يمكن تمثيل مجموعة من الكلمات المتشابهة دلاليًا في صورة عناقيد من العقد المتصلة معًا بواسطة حواف عالية الوزن.
يطلق على عناقيد العقد كذلك المجتمعات (Communities).
مخرج المخطط هو مجموعة بسيطة من الرؤوس والحواف الموزونة. لم تُجرى عملية التجميع حتى الآن لإنشاء المجتمعات. في الشكل أدناه تُستخدم ألوان مختلفة لتمييز المجتمعات في المخطط المذكور في المثال السابق.

خوارزمية لوفان Louvain Algorithm
تتضمن مكتبة Networkx العديد من الخوارزميات لتحليل المخطط والبحث عن المجتمعات.
واحدة من الخيارات الأكثر فعالية هي خوارزمية لوفان التي تعمل عير تحريك العقد بين المجتمعات حتى تجد بنية المجتمع التي تمثل الربط الأفضل في الشبكة الضمنية.
دالة Get_communities()
تستخدم الدالة الآتية خوارزمية لوفان للبحث عن المجتمعات في المخطط المبني على الكلمات، تحسب الدالة كذلك مؤشر الأهمية لكل مجتمع على حدة. ثم تكون المخرجات في صورة قاموسين:
- Word_to_coomunity الذي يربط الكلمة بالمجتمع.
- Word_scores الذي يربط المجتمع بدرجة الأهمية.
الدرجة تساوي مجموع تكرار الكلمات في المجتمع. على سبيل المثال، إذا كان المجتمع يتضمن ثلاثة كلمات تظهر 5 و6 و8 مرات في النص. فإن مؤشر المجتمع حينئذٍ يساوي 19. ومن ناحية المفهوم، يمثل المؤشر جزءًا من النص الذي يضمه المجتمع.


الآن بعد ربط كل الكلمات بالمجتمع وربط المجتمع بمؤشر الأهمية ستكون الخطوة التالية هي استخدام هذه المعلومات لتقييم أهمية كل جملة في المستند الأصلي.
دالة evaluate_sentences() مصممة لهذا الغرض.
دالة evaluate_sentences()
تبدأ الدالة بتقسيم المستند إلى جمل، ثم حساب مؤشر الأهمية لكل جملة، استنادًا إلى الكلمات التي تتضمنها. تكتسب كل كلمة مؤشر الأهمية من المجتمع الذي تنتمي إليه.
على سبيل المثال، لديك جملة مكونة من خمسة كلمات w1,w2,w3,w4,w5 الكلمتان 1 و2 تنتميان إلى مجتمع مؤشر قيمته 25، والكلمتان 3و4 تنتميان إلى مجتمع بمؤشر قيمته 30، والكلمة 5 تنتمي إلى مجتمع بمؤشر قيمته 15 مجموع مؤشرات الجمل هو 25+25+30+30+15=125 تستخدم الدالة بعد ذلك هذه المؤشرات لتصنيف الجمل في ترتيب تنازلي من الأكثر إلى الأقل أهمية.


يتضمن المستند الأصلي إجمالي 61 جملة ويستخدم المقطع البرمجي التالي للعثور على الجمل الثلاثة الأكثر أهمية من بين هذه الجمل:
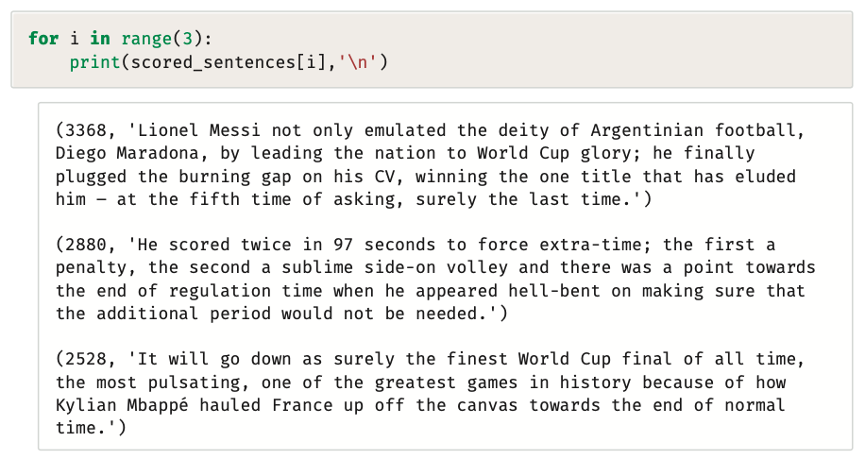

النتائج تؤكد أن هذه المنهجية تحدد بنجاح الجمل الأساسية التي تستنبط النقاط الرئيسي في المستند الأصلي مع تعيين مؤشرات أقل للجمل الأقل دلالة. تطبق المنهجية نفسها كما هي لتوليد ملخص لأي وثيقة محددة.
بإمكانك مراجعة محتوى موضوع “توليد النص” بدايةً من عنوان “استخدام توليد اللغات الطبيعية المبني على الاختيار” وحتى نهاية هذا القسم، من خلال الرابط التالي:
استخدام توليد اللغات الطبيعية المبني على القواعد لإنشاء روبوت الدردشة (Using Rule-Based NLG to Create a Chatbot)
في هذا القسم، ستصمم روبوت دردشة (Chatbot) وفق المسار المحدد الموصي به بالجمع بين قواعد المعرفة الرئيسة للأسئلة والأجوبة والنموذج العصبي تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT) ويشير هذا إلى أن نقل التعلم المستخدم في تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT) له البنية نفسها كما في تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات all-MiniLM-L6-v2 وسوف يُهيأ بشكل دقيق لمهمة أخرى غير تحليل المشاعر وهي توليد اللغات الطبيعية.
- تحميل نموذج تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات المدرب مسبقًا Load the Pre-Trained SBERT Model
الخطوة الأولى هي تحميل نموذج تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT)المدرب مسبقًا:

- إنشاء قاعدة معرفية بسيطة Create a Simple Knowledge Base
الخطوة الثانية هي إنشاء قاعدة معرفة بسيطة لتحديد النص البرمجي المكون من الأسئلة والأجوبة التي يستخدمها روبوت الدردشة.
يتضمن النص البرمجي 4 أسئلة (السؤال 1 إلى 4) والأجوبة على كل سؤال (الإجابة 1 إلى 4).
كل إجابة مكونة من مجموعة من الخيارات كل خيار يتكون من قيمتين فقط، تمثل القيمة الثانية السؤال التالي الذي يستخدمه روبوت الدردشة اذا كان هو السؤال الأخير ستصبح القيمة الثانية خالية، هذه الخيارات تمثل الإجابات الصحيحة المحتملة على الأسئلة المعنية بها.
على سبيل المثال، الإجابة على السؤال الثاني لها خياران محتملان [“java”,None]and[“python”,None](]”جافا”، لا يوجد[ و ]”البايثون”، لا يوجد[ ) كل خيار مكون من قيمتين:
- النص الحقيقي للإجابة المقبولة مثل: Java (جافا) أو Courses on Marketing دورات (تدريبية في السوق).
- معرف يشير إلى السؤال التالي الذي سيطرحه روبوت الدردشة عند تحديد هذا الخيار. على سبيل المثال، إذا حدد المستخدم خيار [“Courses on Engineering”, “3”] ]”دورات تدريبية في الهندسة” ، “3”[ كإجابة على السؤال الأول يكون السؤال التالي الذي سيطرحه روبوت الدردشة هو السؤال الثالث.
يمكن توسيع قاعدة المعرفة البسيطة لتشمل مستويات أكثر من الأسئلة والأجوبة وتجعل روبوت الدردشة أكثر ذكاءً.

دالة chat()
في النهاية، تستخدم دالة chat() لمعالجة قاعدة المعرفة وتنفيذ روبوت الدردشة، بعد طرح السؤال، يقرأ روبوت الدردشة رد المستخدم.
- إن كان الرد مشابهًا دلاليًا لأحد خيارات الإجابات المقبولة لهذا السؤال، يحدد ذلك الخيار وينتقل روبوت الدردشة إلى السؤال التالي إن لم يتشابه الرد مع أي من الخيارات.
- يُطلب من المستخدم إعادة صياغة الرد.
تستخدم دالة تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT) لتقييم مؤشر التشابه الدلالي بين الرد وكل الخيارات المرشحة يعد الخيار متشابهًا إذا كان المؤشر أعلى من متغير الحد الأدنى sim_Ibound.


انظر إلى التفاعلين التاليين بين روبوت الدردشة والمستخدم:

في التفاعل الأول، يفهم روبوت الدردشة أن المستخدم يبحث عن دورات تدريبية في التسويق وكذلك روبوت الدردشة ذكي بالقدر الكافي ليفهم أن المصطلح SEO يشبه دلاليًا مصطلح Search Engine Optimization (تحسين محركات البحث) مما يؤدي إلى انهاء المناقشة بنجاح.

في التفاعل الثاني يفهم روبوت الدردشة أن Cooking Classes (دروس الطهي) لا تشبه دلاليًا الخيارات الموجودة في قاعدة المعرفة وهو ذكي بالقدر الكافي ليفهم أن Software Courses (الدورات التدريبية في البرمجة) يجب ان ترتبط بخيار Courses on Computer Programming (الدورات التدريبية في برمجة الحاسب).
الجزء الأخير من التفاعل يسلط الضوء على نقاط الضعف يربط روبوت الدردشة بين رد المستخدم C++ وJava. على الرغم من أن لغتي البرمجة مرتبطتان بالفعل ويمكن القول بأنهما الأكثر ارتباطًا من لغتي البايثون و C++ إلا أن الرد المناسب يجب أن يوضح أن روبوت الدردشة لا يتمتع بالدراية الكافية للتوصية بالدورات التدريبية في لغة C++.
إحدى الطرائق لمعالجة هذا القصور هي استخدام التشابه بين المفردات بدلاً من التشابه الدلالي للمقارنة بين الردود والخيارات ذات الصلة ببعض الأسئلة.
استخدام تعلُّم الآلة لتوليد نص واقعي (Using Machine Learning to Generate Realistic Text)
الطرائق الموضحة بالأقسام السابقة تستخدم القوالب والقواعد أو تقنيات التحديد لتوليد النصوص للتطبيقات المختلفة.
في هذا القسم، ستتعرف على أحدث تقنيات تعلن الآلة المستخدمة في توليد اللغات الطبيعية (NLG).

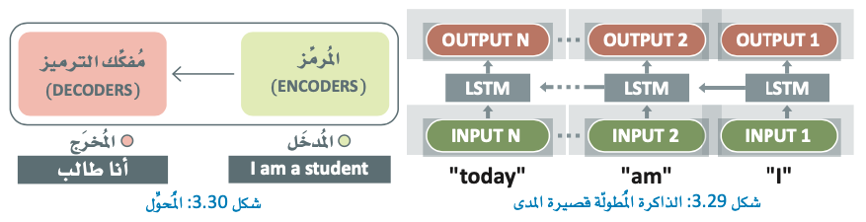
المحولات Transformers
المحولات مناسبة لمهام توليد اللغات الطبيعية لقدرتها على معالجة البيانات المدخلة المتسلسلة بكفاءة.
في نموذج المحولات تمرر البيانات المدخلة عبر المُرمز الذي يحول المدخلات إلى تمثيل مستمر، ثم يمرر التمثيل عبر مفكك الترميز الذي يولد التسلسل المخرج.
إحدى الخصائص الرئيسة لهذه النماذج هي استخدام آليات الانتباه التي تسمح للنموذج بالتركيز على الأجزاء المهمة من التسلسل في حين تتجاهل الأجزاء الأقل دلالة.
أظهرت نماذج المحولات كفاءة في توليد النص عالي الدقة للعديد من مهام توليد اللغات الطبيعية بما في ذلك ترجمة الآلة والتلخيص والإجابة على الأسئلة.
نموذج الإصدار الثاني من المحول التوليدي مسبق التدريب GPT-2 Model
في هذا القسم، ستستخدم الإصدار الثاني من المحول التوليدي مسبق التدريب (GPT-2) وهو نموذج لغوي قوي طورته شركة أوبن أي آي (Open AI) لتوليد النصوص المستندة إلى النص التلقيني المدخل بواسطة المستخدم.
الإصدار الثاني من المحول التوليدي مسبق التدريبGenerative Pre-training Transformer 2 – GOT-2) مدرب على مجموعة بيانات تضم أكثر من ثمان ملايين صفحة ويب ويتميز بالقدرة على إنشاء النصوص البشرية بعدة لغات وأساليب.
بنية الإصدار الثاني من المحول التوليدي مسبق التدريب GPT-2 المبنية على المحول تسمح بتحديد التبعيات (Dependencies) بعيدة المدى وتوليد النصوص المتسقة، وهو مدرب للتنبؤ بالكلمة التالية وفقًا لكل الكلمات السابقة ضمن النص وبالتالي يمكن استخدام النموذج لتوليد نصوص طويلة جدًا عبر التنبؤ المستمر وإضافة المزيد من الكلمات.

يقدم النص التالي كأساس يستند إليه الإصدار الثاني من المحول التوليدي مسبق التدريب (GPT-2):


يحقق هذا مخرجات أكثر تنوعًا مع الحفاظ على دقة وسلامة النص المولد حيث يستخدم النص مفردات غنية وهو سليم نحويًا. يسمح الإصدار الثاني من المحول التوليدي مسبق التدريب (GPT-2) بتخصيص المخرج بشكل أفضل.
يتضح ذلك عند استخدام متغير temperature (درجة الحرارة) الذي يسمح للنموذج بتقبل المزيد من المخاطر بل وأحيانًا اختيار بعض الكلمات الأقل احتمالاً. القيم الأعلى لهذا المتغير تؤدي إلى نصوص أكثر تنوعًا، مثل:

ومع ذلك، إذا كانت درجة الحرارة مرتفعة للغاية فإن النموذج سيتجاهل الإرشادات الأساسية التي تظهر في المدخل الأولي (Original Seed) ويولد مخرجًا أقل واقعية وليس له معنى:

بإمكانك مراجعة محتوى موضوع “توليد النص” بدايةً من عنوان “استخدام توليد اللغات الطبيعية المبني على القواعد لإنشاء روبوت الدردشة” وحتى نهاية الموضوع، من خلال الرابط التالي:
اختبر تحصيلك لمحتوى الموضوع من خلال الرابط التالي:
الواجب الإلكتروني
إلى هنا يكون قد انتهى موضوع “توليد النص“، لا تنسوا مراجعة أهداف التعلُّم أعلى المقال، وانتظرونا في الموضوع القادم!