مكتبات البايثون لتحليل البيانات | الوحدة الثالثة | الدرس الثاني
مكتبات البايثون لتحليل البيانات هو عنوان الدرس الثاني من الوحدة الثالثة التي تحمل اسم “التحليل الاستكشافي للبيانات” من مقرر “علم البيانات”.
ستتعرف في هذا الموضوع على مكتبة نمباي، ومكتبة بانداس في لغة البايثون، والتمييز بينهما، وكيفية تطوير برنامج لتحليل البيانات باستخدام مكتبات البرمجة، بالإضافة إلى كيفية استخدام المكتبات، وتوظيف الفهرسة (Indexing) مع الكائنات.

لذا قم بقراءة أهداف التعلُّم بعناية، ثم أعد قراءتها وتأكَّد من تحصيل كافة محتوياتها بعد انتهائك من دراسة الموضوع.
أهداف التعلُّم
- معرفة مكتبة نمباي في لغة البايثون، وكيفية التعامل معها.
- معرفة مكتبة بانداس في لغة البايثون، وكيفية التعامل معها.
- التمييز بين مكتبتي نمباي، وبانداس.
- تطوير برنامج لتحليل البيانات باستخدام مكتبات البرمجة.
- استخدام كائن المتسلسلة (Series Object) عبر تضمين مكتبة بانداس.
- استخدام كاين إطار البيانات (Data Frame)، عبر تضمين ملف إكسل في مفكرة جوبيتر.
- استخدام الفهرسة في كائن المتسلسلة، وكائن إطار البيانات.
- تنظيف البيانات وإصلاحها.
هيا لنبدأ!
مكتبة نمباي (NumPy Library)
إلى ماذا يرمز اسم مكتبة NumPy؟
- يرمز إلى البايثون العددي Numerical Python.
- هي مكتبة قياسية للعمل على البيانات العددية في البايثون.
- يمكن استخدامها لإجراء مجموعة متنوعة من العمليات الرياضية على المصفوفات.

تعريف هام
الوظيفة (Method)
هي دالة مرتبطة بكائن (Object) ويتم تعريفها داخل الفئة (Class). على سبيل المثال: np.add(arr1, arr2).
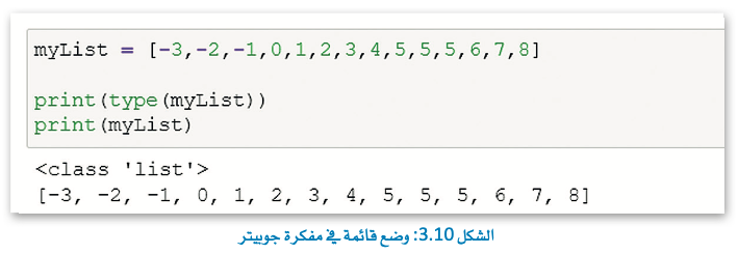
ابدأ بإنشاء قائمة بسيطة خاصة بك في مفكرة جوبيتر.
تعريف هام
المصفوفة (Array)
هي نوع من البيانات يمكنه الاحتفاظ بعدد ثابت من القيم التي لها نفس نوع البيانات.
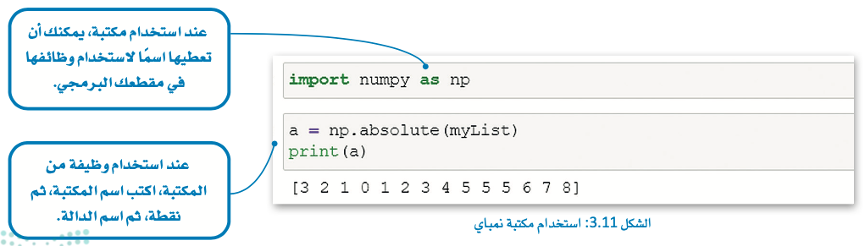
استخدام القيمة المطلقة absolute() لطباعة القيم المطلقة للقائمة.
لمعرفة المزيد من المعلومات عن مكتبة NumPy، قم بالاطّلاع على الرابط التالي:
مكتبة بانداس (Pandas Library)
تأخذ مكتبة بانداس البيانات وتنشئ كائن البايثون، وهناك نوعان رئيسان من الكائنات:
- المتسلسلة (series): عبارة عن مصفوفة أحادية البعد قادرة على حمل أي نوع من البيانات (الأعداد الصحيحة (Integer)) ، السلاسل النصية (String)، الأرقام العشرية (Float)، كائنات البايثون وغيرها.
- إطار البيانات (Data Frame) : هو هيكل بينات ثنائي الأبعاد يبدو مشابهًا جدًا لجدول البيانات في ورقة عمل إكسل.
لكل كائن أساليبه وسماته الخاصة. يمكنك إنشاء متسلسلة أو إطار بيانات من الصفر (من القوائم والقواميس وما إلى ذلك) كما يمكن استيراد البيانات من مصادر البيانات مثل: إكسل، CSV، SQL، JSON، والمزيد.
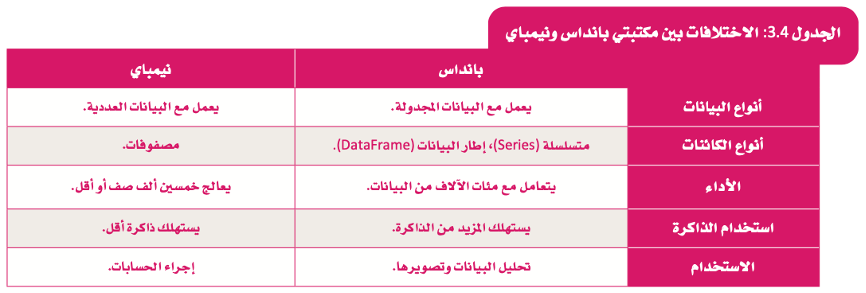
مقارنة بين مكتبة NumPy ومكتبة Pandas.
لمعرفة المزيد من المعلومات عن مكتبة Pandas، قم بالاطّلاع على الرابط التالي:
بإمكانك مراجعة محتوى موضوع “مكتبات البايثون لتحليل البيانات” من بدايته وحتى نهاية هذا القسم، من خلال الرابط التالي:
كائن المتسلسلة (Series Object)
الآن سنقوم بتحويل هذه القائمة إلى كائن المتسلسلة، للقيام بذلك عليك تضمين مكتبة بانداس في مفكرتك ولاستخدام مكتبة بايثون، يمكنك إضافة كلمة استيراد (Import) واسم المكتبة في بداية مقطعك البرمجي.
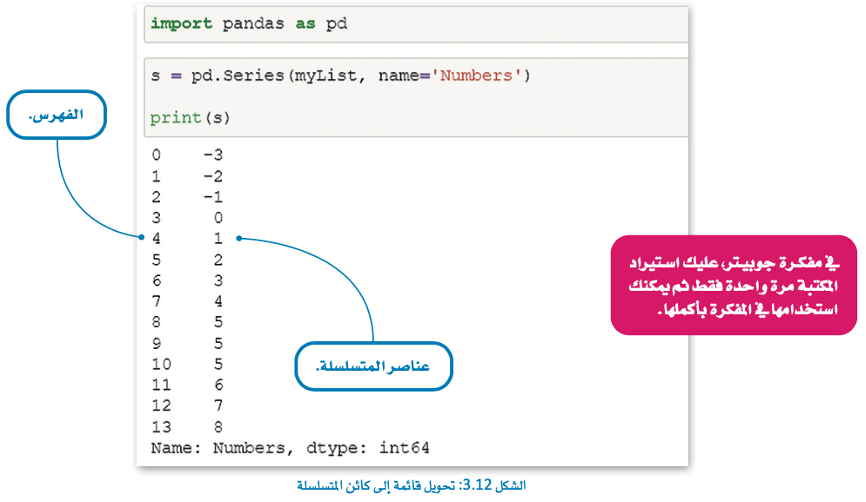
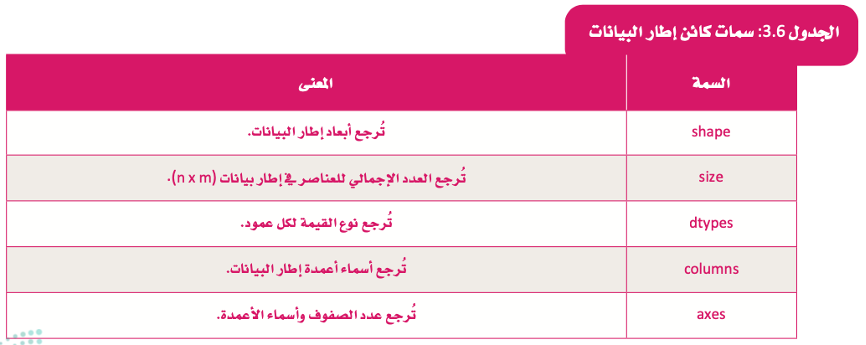
سمات كائن المتسلسلة (Attributes of Series Object)
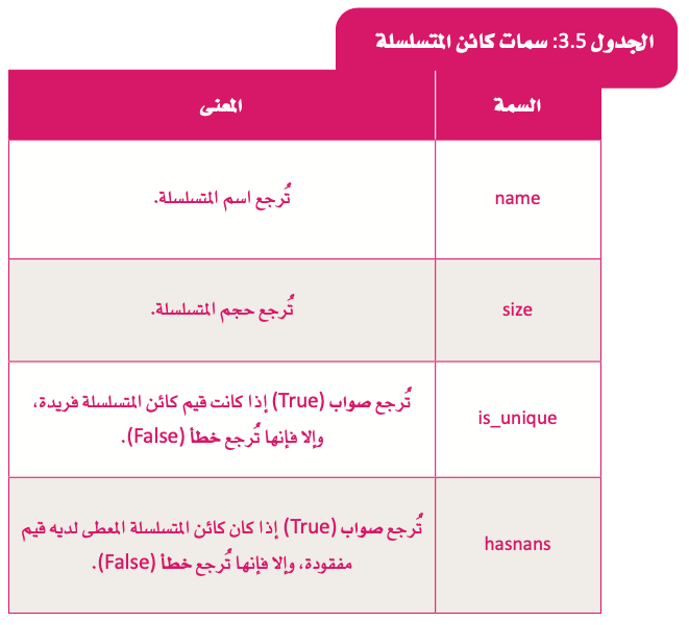
في الجدول التالي يتم تقديم بعض السمات الأكثر شيوعًا التي يمكِنك استخدامها لكائن المتسلسلة.
تعريف هام
السمة (Attribute)
قيمة مرتبطة بالكائن الذي يشار إليه بالاسم باستخدام تعبيرات منقطة. على سبيل المثال، إذا كان الكائن طالبًا (student) وكانت السمة درجة (grade). فسيتم الإشارة إليها student.grade.
لاحظ أن
في الحوسبة، NaN ترمز إلى ليس رقمًا (Not a Number).
طبّق بعض هذه السمات في كائن المتسلسلة.

كائن إطار البيانات (Data Frame Object)
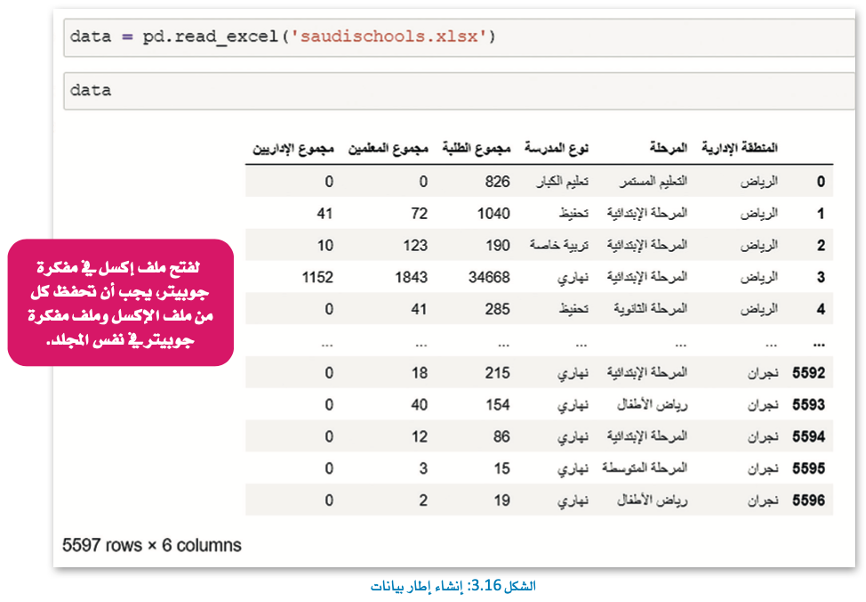
الأداة التحليلية الأكثر شيوعًا واستخدمًا هي إكسل، يمكنك العمل مع ملفات إكسل في مفكرة جوبيتر باستخدام مكتبة بانداس، لفتح ملف إكسل في مفكرة جوبيتر تحتاج إلى أن تكون هذه الملفات (ملف الإكسل والمفكرة) في نفس المجلد.
مكتبة نظام التشغيل (OS Library)
للتحقق من ملف العمل الخاص بك، يمكنك استخدام مكتبة نظام التشغيل (OS) ، حيث أنها توفر في بايثون وظائف لإنشاء وإزالة دليل (مجلد)، وجلب محتوياته، وتغيير أو تحديد المجلد الحالي، إلى آخره.

هذا هو ملف الإكسل الخاص بك.
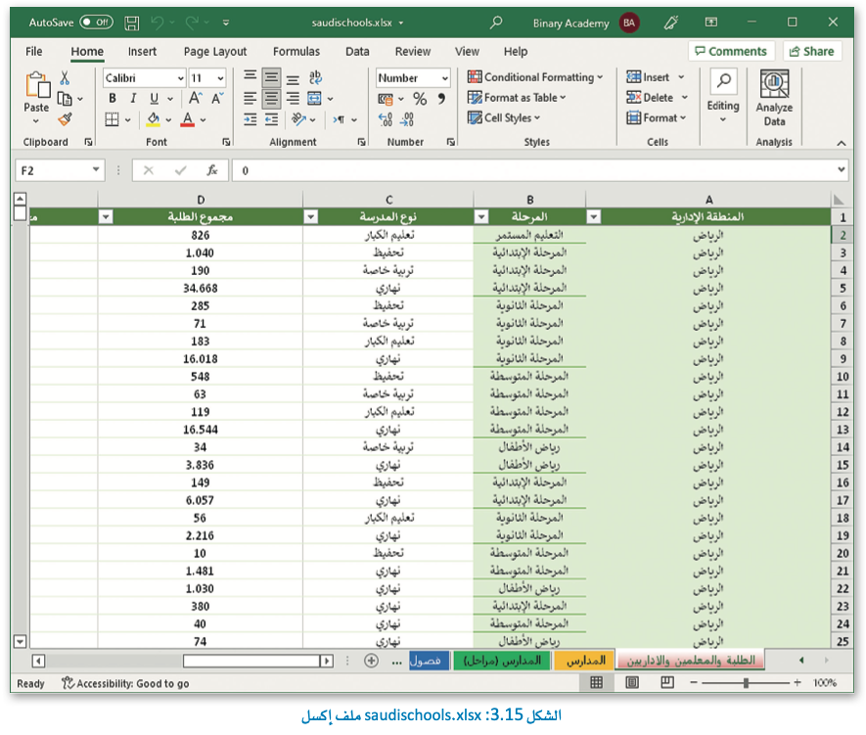

الآن، ستقوم بتحويل ملف الإكسل الآتي إلى إطار البيانات لمعالجة بياناته.

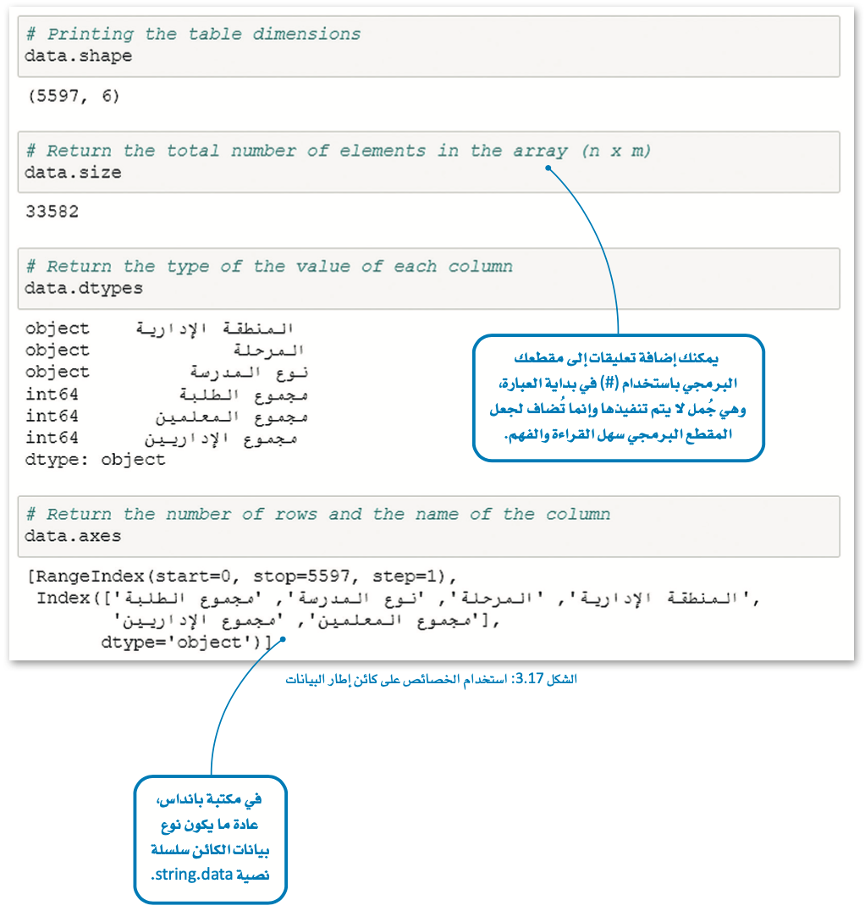
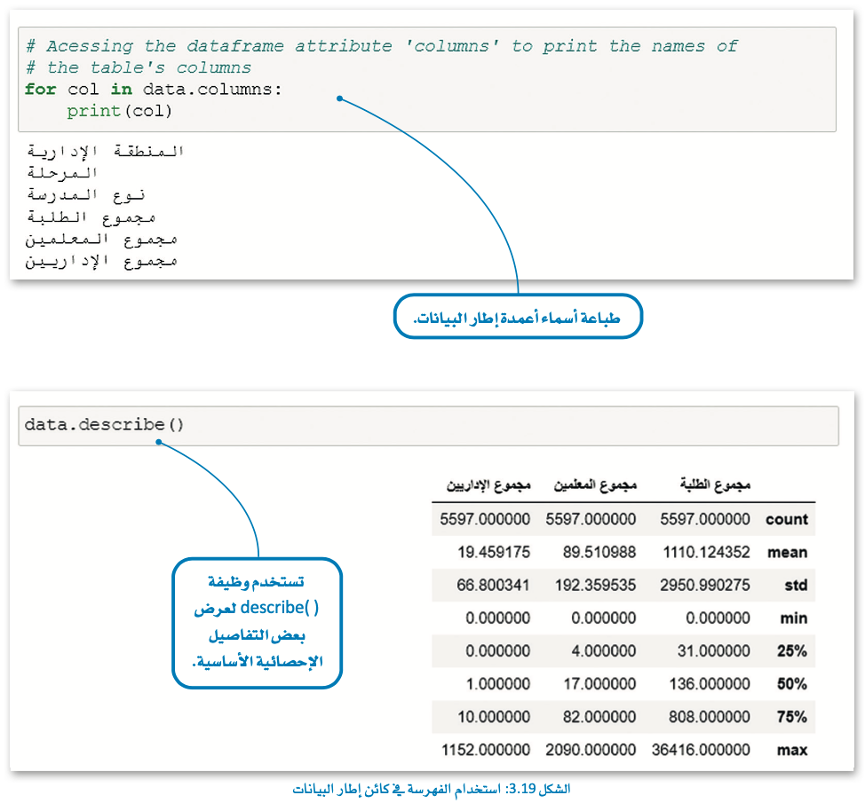
سمات كائن إطار البيانات (Attribute of a Data Frame Object)
في الجدول الآتي، يتم تقديم بعض السمات الأكثر شيوعًا، والتي يمكنك توظيفها في الحصول على معلومات حول إطار البيانات.
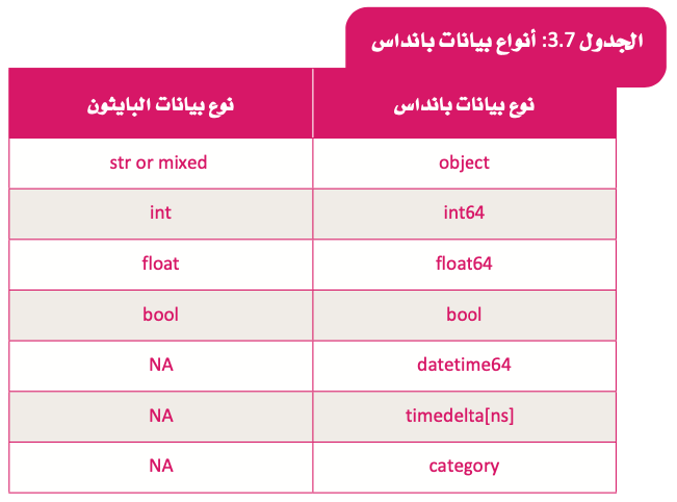
أنواع بيانات بانداس
الفهرسة (Indexing)
الفهرس (Index) هو قائمة بالأعداد الصحيحة أو التسميات التي تستخدمها لتحديد الصفوف أو الأعمدة بشكل فريد.
في بانداس، تتضمن بشكل أساسي اختيار صفوف وأعمدة محددة من البيانات أو إطار البيانات، حيث يمكن اختيار جميع الصفوف وبعض الأعمدة، أو اختيار بعض الصفوف وجميع الأعمدة، أو بعض كل من صف وعمود.
كذلك يمكن تعريف مصطلح الفهرسة على أنه اختيار المجموعة الفرعية (Subset Selection).
وظائف الفهرسة
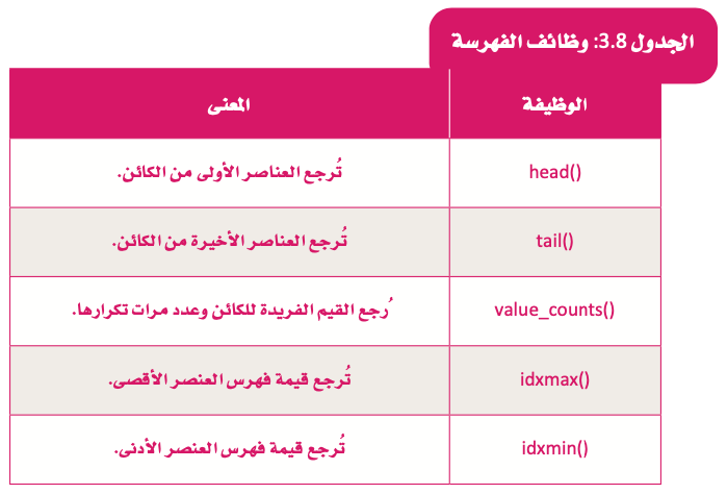
استخدام الفهرسة في كائن المتسلسلة (Using Indexing in a Series Object)
طبق وظائف الفهرسة هذه على كائن المتسلسلة الذي قمت بإنشائه، اطبع كائن المتسلسلة أولاً، لتذكر محتوياته.

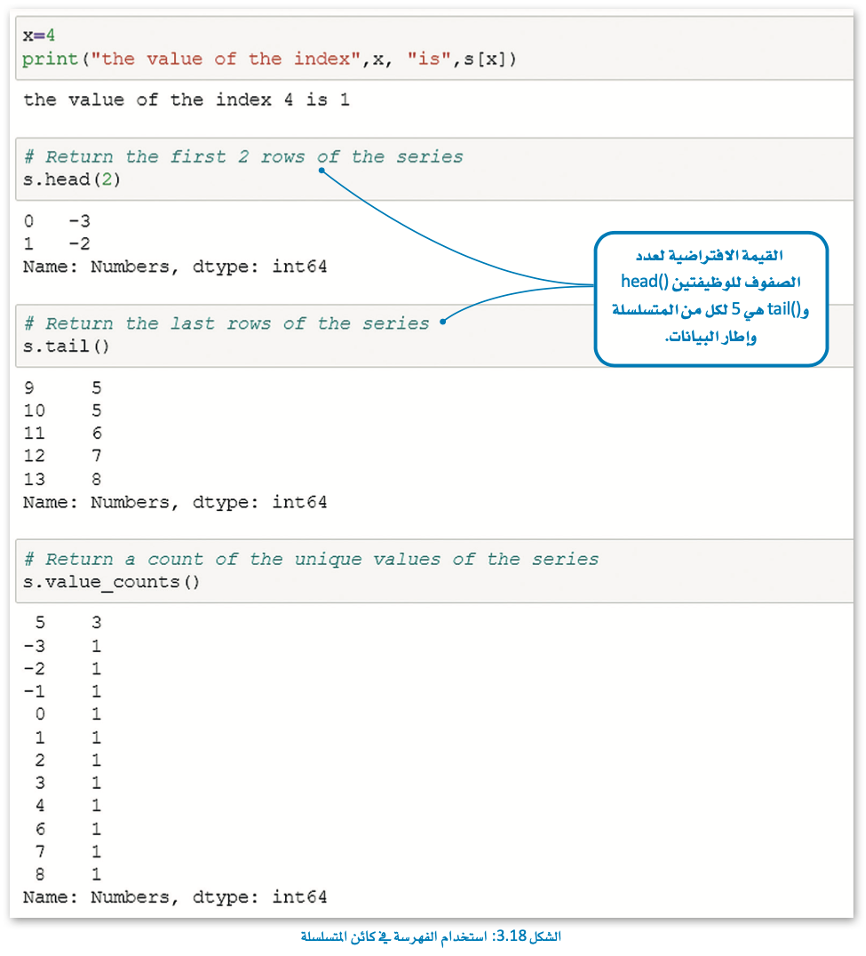
بإمكانك مراجعة محتوى موضوع “مكتبات البايثون لتحليل البيانات” بدايةً من عنوان “كائن المتسلسلة” وحتى هذه النقطة، من خلال الرابط التالي:
استخدام الفهرسة في كائن إطار البيانات (Using Indexing in DataFrame Object)
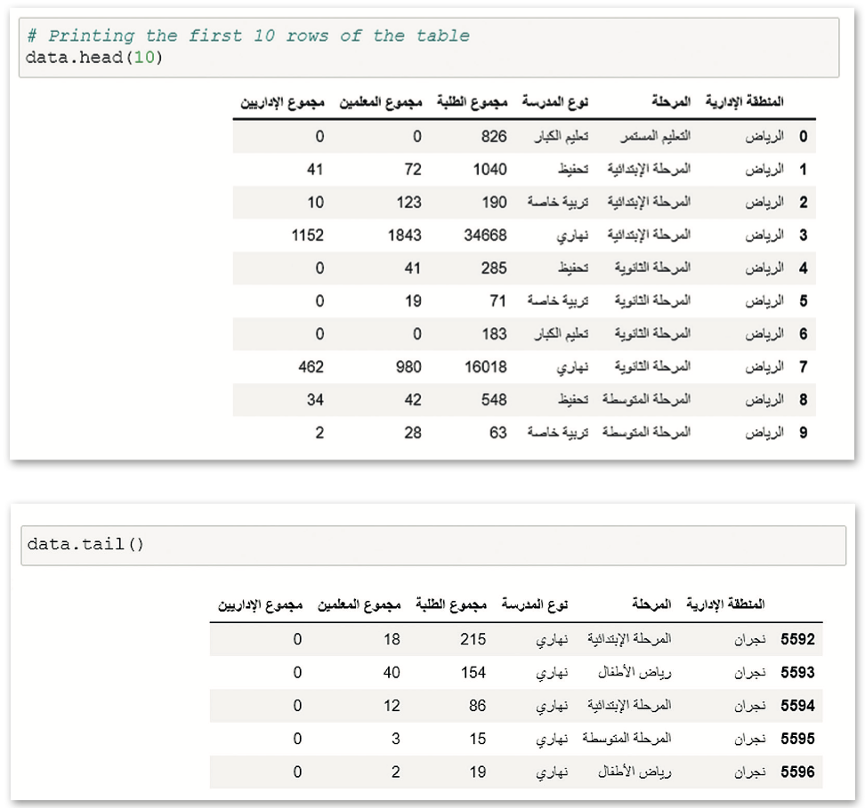
تصفية البيانات أو اختيار مجموعة بيانات جزئية (Filtering Data or Subset Selection)
عندما تحتاج بعض البيانات وليس جميعها كيف يتحقق ذلك؟
من خلال إضافة المرشحات تستطيع عزل بعض البيانات المحددة، وأساليب اختيار مجموعة جزئية من اطار البيانات أو متسلسلة. من أهم تلك الأساليب:
- الأسلوب الأسهل (الفهرسة المنطقية).
- الأسلوب الأكثر قوة: Loc ، iLoc.
تعريف هام
تصفية البيانات (Attribute)
تصفية البيانات هو عملية اختيار جزء أصغر من مجموعة البيانات الخاصة بك واستخدام تلك المجموعة الجزئية للعرض أو التحليل.
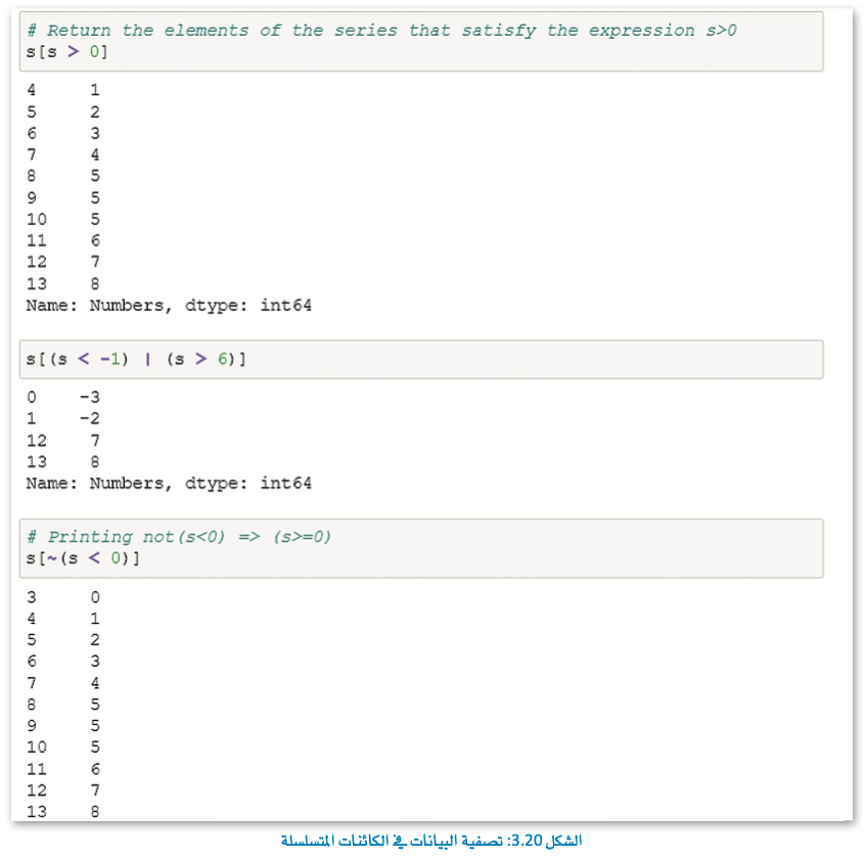
الفهرسة المنطقية (Boolean Indexing)
هي نوع من الفهرسة التي تستخدم القيم الفعلية لمجموعة البيانات، وفيها تحتاج إلى استخدام المعاملات المنطقية (Boolean Operator) ، وتكتب المعاملات المنطقية بشكل مختلف في مفكرة جوبيتر عن بايثون.

أمثلة على تصفية البيانات في كائن المتسلسلة
الفهرسة مع أسلوب Loc وIndexing with Loc and Iloc Methods
تعد طريقتي iloc وloc ضمن الطلاق الأكثر شيوعًا للفهرسة في مكتبة بانداس.
- Loc: يختار الصفوف والأعمدة مع مسميات محددة (أسماء الأعمدة).
- Iloc: يختار الصفوف والأعمدة في مواضع الأعداد الصحيحة المحددة (أرقام الصفوف والأعمدة).
إليك بعض الأمثلة على استخدام كائن إطار البيانات بأسلوب loc( ).
في هذا المثال، سنستخدم طريقة loc() لطباعة الصفوف الخمسة الأولى من عمودين محددين.
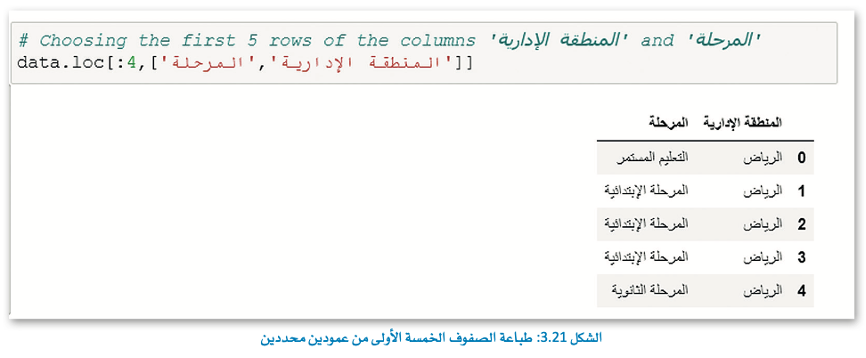
في هذا المثال، ستقوم بطباعة صفوف إطار البيانات التي لها قيمة محددة في عمود معين.
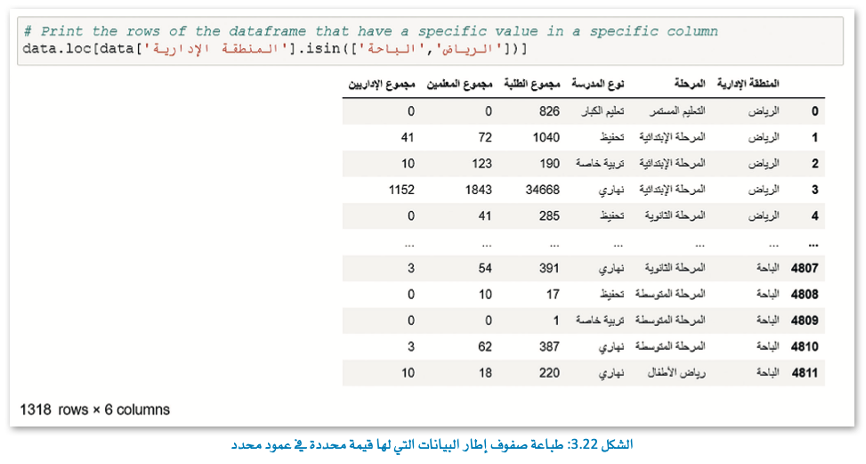
في هذا المثال ستنشئ إطار بيانات جديد يسمى studentReg، وسيحتوي إطار البيانات هذا على عمودين: عمود واحد للمنطقة وعمود للطلبة.
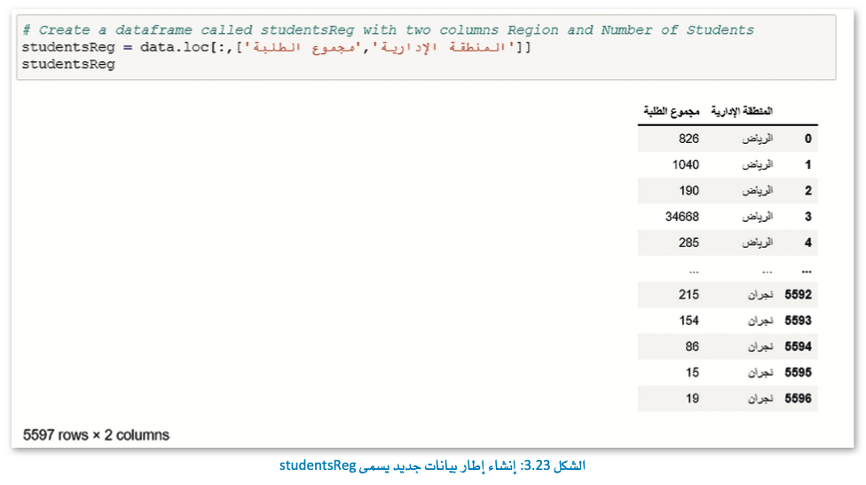
الآن، سنستخدم طريقة iloc( ) لتحديد جميع عناصر الصف الأول من إطار البيانات.
في المثال التالي، ستطبع عناصر محددة من إطار البيانات.
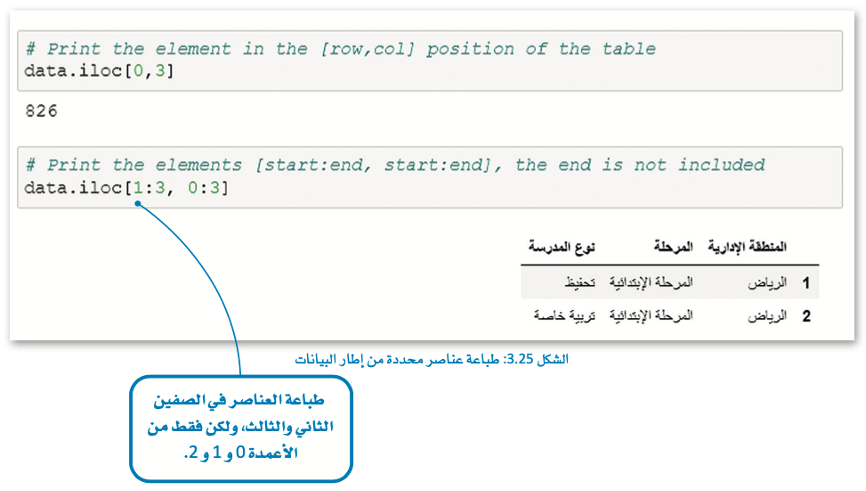
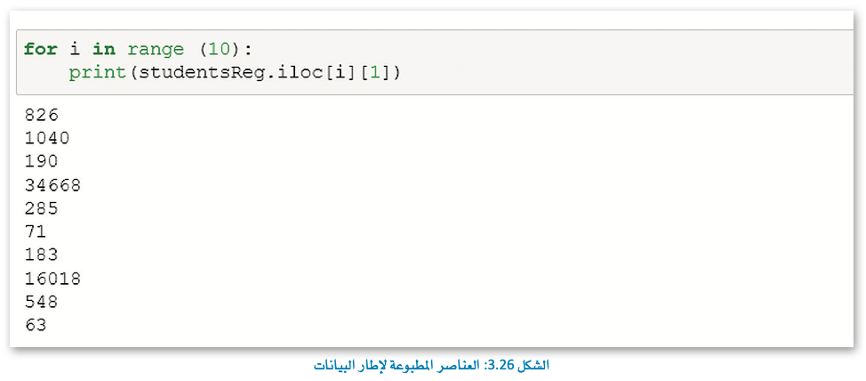
في هذا المثال، سنستخدم حلقة for لطباعة الصفوف العشرة الأولى من العمود الأول من إطار بيانات StudentReg.
المجموعات والتجميع (Grouping and Aggregation)
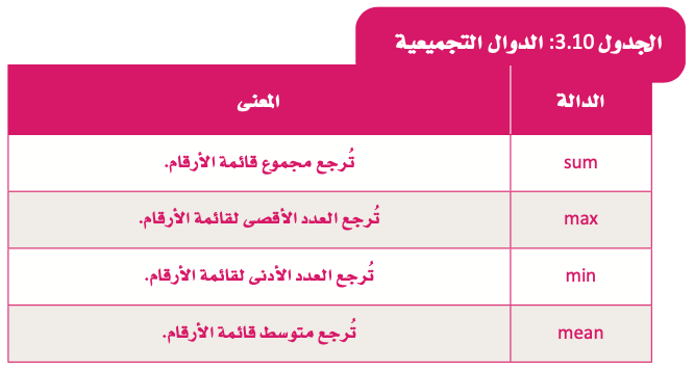
ما هي دالة التجميع؟
- هي دالة تقوم بحسابات رياضية مع قيم صفوف متعددة والتي يتم تجميعها معًا، ونتيجة لذلك ترجع قيمة موجزة واحدة.
- هي عملية وضع عناصر مجموعة البيانات في مجموعات بناءً على بعض المعايير وتطبيق الوظائف على هده المجموعات.
أمثلة على دوال التجميع الأكثر شيوعًا.
كيف يتم تنفيذ التجميع في مكتبة بانداس؟
باستخدام وظيفة def.groupby().
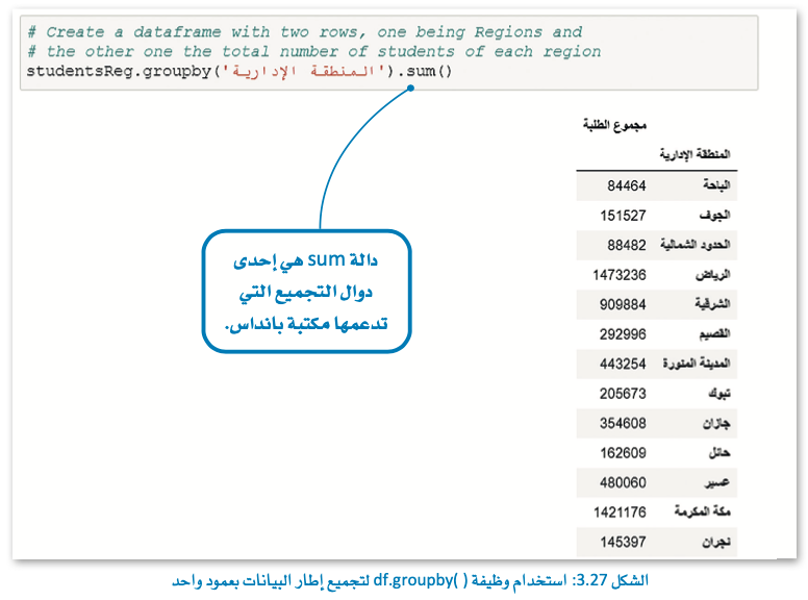
على سبيل المثال، تخيل أن لديك مجموعة بيانات لأفضل هدافي كرة السلة في كل العصور. إذا كنت ترغب في معرفة عدد اللاعبين في مجموعة البيانات هذه لفريق معين، فيمكنك تجميع هذه البيانات حسب عمود “الفريق” وتطبيق دالة المجموع SUM() على البيانات المجمعة.
وظيفة Groupby GroupbyMethod
باستخدام وظيفة groupby() يمكنك تقسيم بياناتك إلى مجموعات مختلفة، ويمكن أن يساعدك هذا في إجراء حسابات لتحليل البيانات بشكل أفضل.
لنشاهد بعض الأمثلة لوظيفة df.groupby() في إطار البيانات الجديد الذي أنشأته.
في هذا المثال، ستقوم بتجميع الطلبة وفقًا لمنطقتهم وتحسب مجموع الطلبة في كل منطقة.
في هذا المثال، سنقوم بتجميع الطلبة وفقًا لمعيارين منطقتهم ومرحلتهم الدراسية وتحسب مجموع الطلبة في كل منطقة.
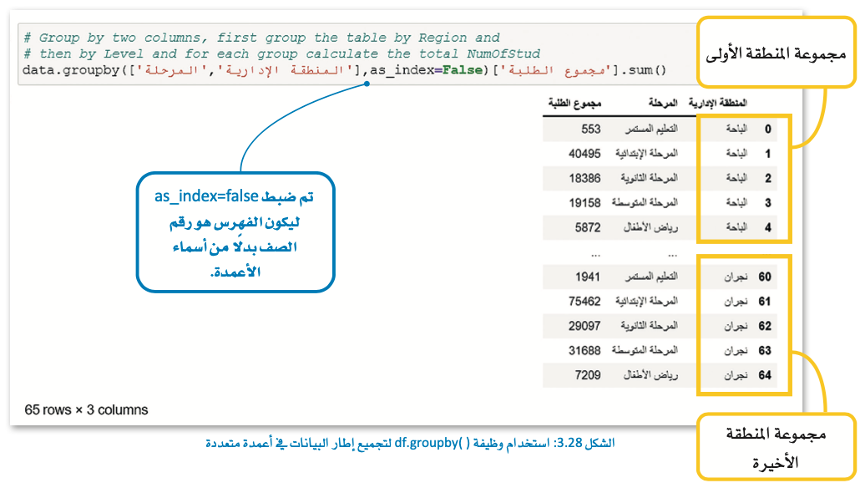
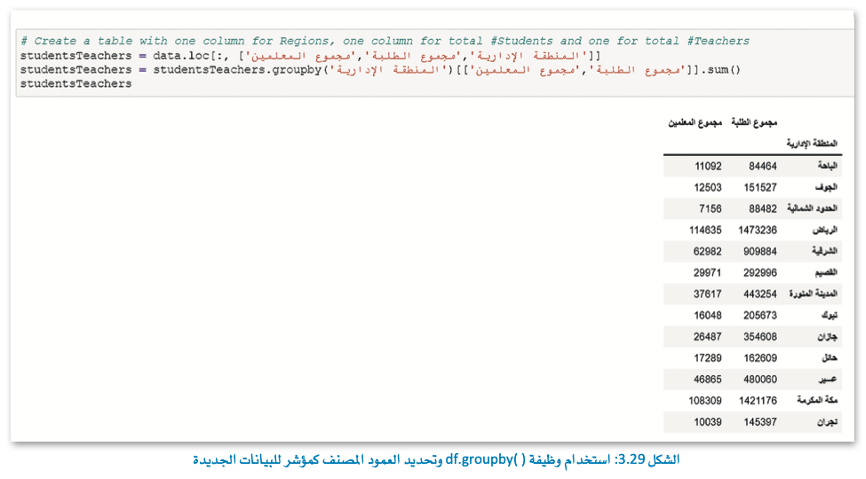
في هذا المثال، سنقوم بإنشاء إطار بيانات جديد للمنطقة وعدد الطلبة وعدد المعلمين ثم تجمع حسب المنطقة وتحسب مجموع الطلبة ومجموع المعلمين في كل منطقة.
بإمكانك مراجعة محتوى موضوع “مكتبات البايثون لتحليل البيانات” بدايةً من عنوان “استخدام الفهرسة في كائن إطار البيانات” وحتى نهاية هذا القسم، من خلال الرابط التالي:
تنظيف البيانات (Data Cleaning)
ماذا يعني مصطلح تنظيف البيانات؟
تنظيف البيانات هو عملية إصلاح أو إزالة للبيانات غير الصحيحة أو المشوشة أو المنسقة بشكل غير صحيح أو المكررة أو غير المكتملة من مجموعة البيانات.
قبل البدء في تحليل البيانات من المهم جدًا أن تكون صحيحة، وهذا يعني أنه يجب إزالة البيانات المكررة أو المشوشة أو غير الدقيقة من مجموعة البيانات الخاصة بك، لكن إذا بقيت هذه البيانات كما هي لن تكون نتائج تحليلها صحيحة.
عملية تنظيف البيانات
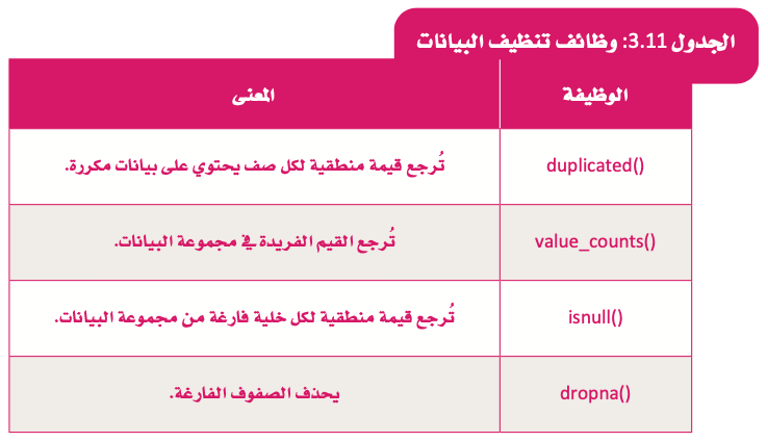
وظائف تنظيف البيانات
لمعرفة المزيد من المعلومات عن تنظيف البيانات، قم بالاطّلاع على الرابط التالي:
البيانات المكررة (Duplicate Data)
ما وظيفة دالة df.duplicated()؟
للتحقق مما إذا كانت مجموعة البيانات الخاصة بك تحتوي على بيانات مكررة وتعطي قيمة منطقية لكل صف حسب احتوائه على بيانات مكررة مثل:
- صواب (True): للبيانات المكررة.
- خطأ (False): للبيانات غير المكررة.
سنرى كيفية التعامل مع الصفوف المكررة في مجموعة البيانات.
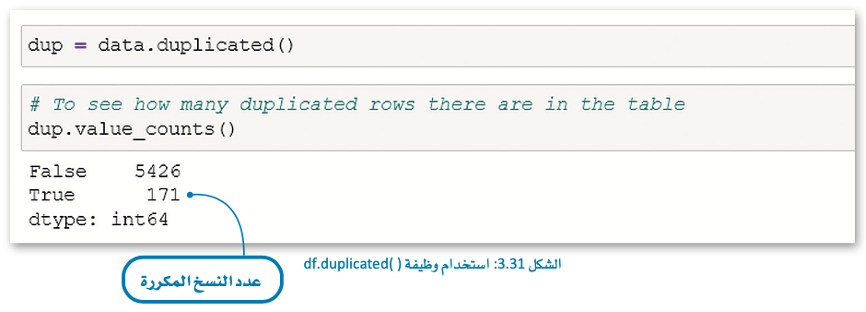
يوجد في مجموعة البيانات الخاصة بك 171 صفًا مكررًا.
كيف يتم حذف الصفوف المكررة؟
باستخدام دالة drop_duplicates() يتم حذف الصفوف المكررة.
بعد حذف الصفوف المكررة، عليك تحديث مجموعة البيانات الخاصة بك للتحقق من إزالة الصفوف المكررة.

الخلايا الفارغة (Empty Cells)
ما وظيفة دالة df.isnull()؟
للتحقق إذا كانت مجموعة البيانات الخاصة بك بها قيم مفقودة، حيث ترجع قيمة منطقية لكل خلية من مجموعة البيانات:
- صواب (True): للخلايا الفارغة.
- خطأ (False): للخلايا الممتلئة.
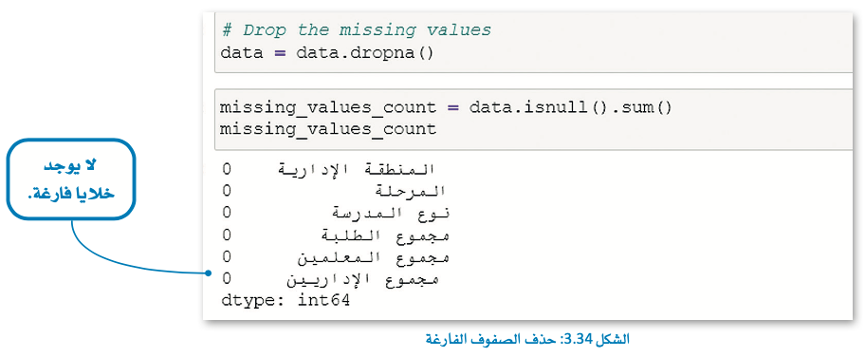
هي هذا المثال، سنحسب الخلايا الفارغة لكل عمود.

يمكنك رؤية عدد الخلايا الفارغة في كل عمود.
كيف يتم حذف الصفوف الفارغة؟
باستخدام دالة dropna().
بعد حذف الصفوف الفارغة، عليك تحديث مجموعة البيانات الخاصة بك للتحقق من إزالة هذه الصفوف.
البيانات الخاطئة (Wrong Data)
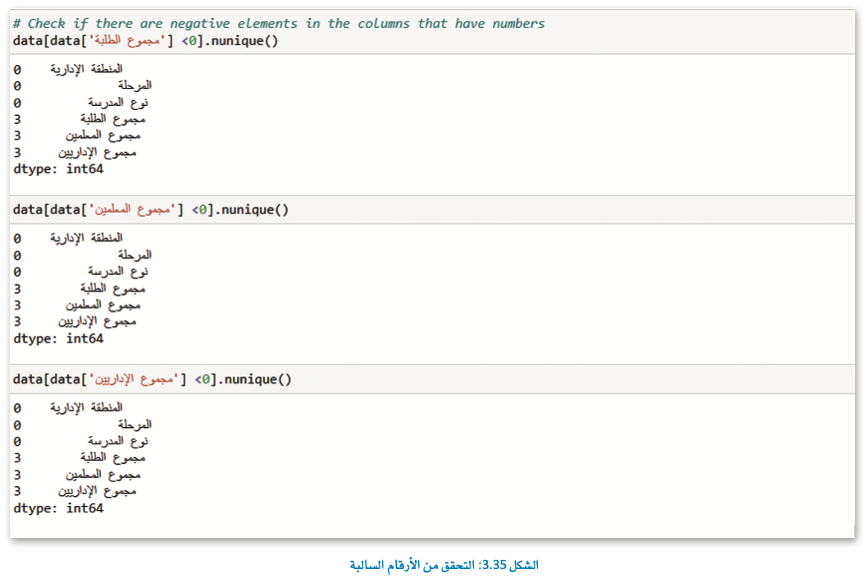
في بعض الأحيان قد تحتوي مجموعة البيانات الخاصة بك على بيانات خاطئة. على سبيل المثال، في مجموعة البيانات الخاصة بك لا يمكنك الحصول على أرقام سالبة في عدد عمود الطلبة، وللتحقق مما إذا كانت مجموعة البيانات الخاصة بك تحتوي على بيانات خاطئة، عليك كتابة مقطع برمجي مخصص على حسب مجموعة البيانات الخاصة بك.
في هذا المثال سنتحقق من الأرقام السالبة في أعمدة مجموعة البيانات.
يعتمد نوع البيانات التي يمكن اعتبارها خاطئة على مجموعة البيانات، عليك أن تقرر ماذا تفعل بهذه البيانات الخاطئة فقد ترغب في حذفها أو استبدالها بقيم أخرى.
اختبر تحصيلك لمحتوى الموضوع من خلال الرابط التالي:
الواجب الإلكتروني
إلى هنا يكون قد انتهى موضوع “مكتبات البايثون لتحليل البيانات“، لا تنسوا مراجعة أهداف التعلُّم أعلى المقال، وانتظرونا في الموضوع القادم!