اتخاذ القرار القائم على القواعد | الوحدة الثانية | الدرس الثالث

اتخاذ القرار القائم على القواعد هو عنوان الدرس الثالث من الوحدة الثانية التي تحمل اسم “خوارزميات الذكاء الاصطناعي” في الفصل الدراسي الأول من مقرر “الذكاء الاصطناعي”.
ستتعرف في هذا الموضوع على الأنظمة القائمة على القواعد، ومفهوم قاعدة المعرفة، وتحديد مزايا وعيوب الأنظمة القائمة على القواعد، بالإضافة إلى تطبيق نظام تشخيص طبي مستندًا إلى القواعد.

لذا قم بقراءة أهداف التعلُّم بعناية، ثم أعد قراءتها وتأكَّد من تحصيل كافة محتوياتها بعد انتهائك من دراسة الموضوع.
أهداف التعلُّم
- معرفة الأنظمة القائمة على القواعد.
- معرفة مفهوم قاعدة المعرِفة.
- تحديد مزايا وعيوب الأنظمة القائمة على القواعد.
- تطبيق نظام تشخيص طبي بسيطًا مستندًا إلى القواعد.
هيا لنبدأ!
الأنظمة القائمة على القواعد (Rule-Based Systems)
تُركز أنظمة الذكاء الاصطناعي القائمة على القواعد على استخدام مجموعة من القواعد المُحدّدة مُسبقًا لاتخاذ القرارات وحل المُشكلات.

الأنظمة الخبيرة (Expert Systems) هي المثال الأكثر شهرة للذكاء الاصطناعي القائم على القواعد، وتعتبر إحدى صور الذكاء الاصطناعي التي طُورت وانتشرت في فترة الثمانينات والتسعينات من القرن الماضي.
غالبًا كانت تُستخدم لأتمتة المهام التي تتطلب عادةً خبرات بشرية مثل: تشخيص الحالات الطبية، تحديد المشكلات التقنية ومعالجتها.
اليوم لم تُعد الأنظمة القائمة على القواعد التقنية هي الأحدث، حيث تفوقت عليها منهجيات الذكاء الاصطناعي الحديثة.
ومع ذلك، لا تزال الأنظمة الخبيرة شائعة الاستخدام في العديد من المجالات نظرًا لقدرتها على الجمع بين الأداء المعقول وعملية اتخاذ القرار البديهة والقابلة للتفسير.
تعريف هام
الأنظمة الخبيرة (Expert Systems)
النظام الخبير هو أحد أنواع الذكاء الاصطناعي الذي يُحاكي قدرة اتّخاذ القرار لدى الخبير البشري. يَستخدِم النظام قاعدة المعرِفة المكوَّنة من قواعد وحقائق ومحركات الاستدلال لتقديم المشورة أو حل المشكلات في مجال معرفي مُحدَّد.

اتخاذ القرار القائم على القواعد
لمعرفة المزيد من المعلومات عن الأنظمة الخبيرة، قم بالاطّلاع على الرابط التالي:
قاعدة المعرفة (Knowledge Base)
تُعد من أحد المكونات الرئيسة لأنظمة الذكاء الاصطناعي القائمة على القواعد.
هي مجموعة من الحقائق والقواعد التي يستخدمها النظام لاتخاذ القرارات.
تُدخل هذه الحقائق في النظام بواسطة الخبراء البشريين المسؤولين عن تحديد المعلومات الأكثر أهمية وتحديد القواعد التي يتبعها النظام، لاتخاذ القرار أو حل المشكلة.
يبدأ النظام الخبير بالتحقق من الحقائق والقواعد في قاعدة البيانات وتطبيقها على الموقف الحالي.
إن لم يتمكن النظام من العثور على تطابق بين الحقائق والقواعد في قاعدة المعرفة، فقد يطلب من المستخدم معلومات إضافية أو إحالة المشكلة إلى خبير بشري لمزيد من المساعدة.
إليك مزايا وعيوب الأنظمة القائمة على القواعد موضحة في الجدول التالي:

ستتعلم في هذا الموضوع على المزيد حول الأنظمة القائمة على القواعد في سياق أحد تطبيقاتها الرئيسة وهو: التشخيص الطبي.
سيعرض النظام تشخيصًا طبيًا وفقًا للأعراض التي تظهر على المريض كما هو موضح بالشكل أدناه. بدءًا بنظام تشخيص بسيط مستند إلى القواعد، وستكتشف بعض الأنظمة الأكثر ذكاءً وكيف يُحقق كل تكرار نتائج أفضل.
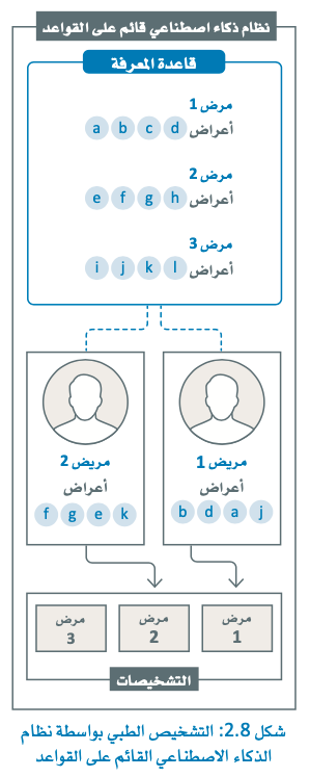
اتخاذ القرار القائم على القواعد
الإصدار 1
في الإصدار الأول ستبني نظامًا بسيطًا قائمًا على القواعد يمكنه تشخيص ثلاث أمراض محتملة: KidneyStones(حصى الكلى)، Appendicitis (التهاب الزائدة الدودية)، Food Poisoning (التسمم الغذائي).
ستكون المدخلات إلى النظام هي قاعدة معرفة بسيطة تربط كل مرض بقائمة من الأعراض المحتملة. يتوفر ذلك في ملف بتنسيق JSON يمكنك تحميله وعرضه كما هو موضح أدناه.

سيتبع الإصدار الأول قاعدة بسيطة وهي:
إذا كان لدى المريض على الأقل ثلاثًا من جميع الأعراض المحتملة للمرض، فيجب إضافة المرض كتشخيص محتمل. يمكنك العثور أدناه على دالة Python التي تستخدم هذه القاعدة لإجراء التشخيص، بالاستناد إلى قاعدة المعرفة المذكورة أعلاه وأعراض المرض والظاهرة على المريض.

في هذه الحالة، تكون قاعدة المعرفة محددة بتعليمات برمجية ثابتة (Hard-Coded) داخل الدالة في شكل عبارات IF. تستخدم هذه العبارات الأعراض الشائعة بين الأمراض الثلاثة للتوصل تدريجيًا إلى التشخيص في أسرع وقت ممكن.
على سبيل المثال، عرض Vomiting (القئ) مشترك بين جميع الأمراض.
لذلك، إذا كانت عبارة IF الأولى صحيحة فقد تم بالفعل حساب أحد الأعراض الثلاثة المطلوبة لجميع الأمراض. بعد ذلك، ستبدأ في البحث عن Abdominal Pain (ألم البطن) المرتبط بمرضين وتستمر بالطريقة نفسها حتى يتم النظر في جميع مجموعات الأعراض الممكنة.
يمكنك بعد ذلك اختبار هذه الدالة على ثلاث مرضى مختلفين:

يتضمن التشخيص الطبي للمريض الأول التسمم الغذائي والتهاب الزائدة الدودية، لأن الأعراض الثلاثة التي تظهر على المريض ترتبط بكلا المرضين.
يُشخص المريض الثاني بحصى الكلى فهو المرض الوحيد الذي تجتمع فيه الأعراض الثلاثة. في النهاية، لا يمكن تشخيص الحالة الطبية للمريض الثالث: لأن الأعراض الثلاثة ظهرت على المريض لا تجتمع في أي مرض من الأمراض الثلاثة.
يتميز الإصدار الأول القائم على القواعد بالبديهة والقابلية للتفسير، كما يتضمن استخدام قاعدة المعرفة والقواعد في التشخيص الطبي دون تحيز أو انحراف عن الخط المعياري. ومع ذلك يشوب هذا الإصدار العديد من العيوب منها:
أولاً: أن قاعدة ثلاث أعراض على الأقل هي تمثيل مبسط للغاية لكيفية التشخيص الطبي على يد الخبير البشري.
ثانيًا: أن قاعدة المعرفة داخل الدالة تكون محددة بتعليمات برمجية ثابتة، وعلى الرغم من أنه يسهُل إنشاء عبارات شرطية بسيطة لقواعد المعرفة الصغيرة، إلا أن المهمة تُصبح أكثر تعقيدًا وتستغرق وقتًا طويلاً عند تشخيص الحالات التي تُعاني من العديد من الأمراض والأعراض المرضية.
بإمكانك مراجعة محتوى موضوع “اتخاذ القرار القائم على القواعد” من بدايته وحتى نهاية هذا القسم، من خلال الرابط التالي:
الإصدار 2
في الإصدار الثاني، ستُعزز مرونة وقابلية تطبيق النظام القائم على القواعد بتمكينه من قراءة قاعدة المعرفة المتغيرة مباشرة من (JSON). سيؤدي هذا إلى الحد الأدنى من عملية الهندسة اليدوية لعبارات IFالشرطية حصب الأعراض ضمن الدالة. وهذا يُعد تحسنّا كبيرًا يجعل النظام قابلاً للتطبيق على قواعد المعرفة الأكبر حجمًا مع تزايد عدد الأمراض والأعراض وفي الأسفل، مثال يوضح قاعدة المعرفة.

قاعدة المعرفة الجديدة هذه أكبر قليلاً من سابقتها. ومع ذلك، يتضح أن محاولة إنشاء عبارات IF الشرطية في هذه الحالة ستكون أصعب بكثير.
على سبيل المثال/ تضمنت قاعدة المعرفة السابقة ربط أحد الأمراض بأربعة أعراض، ومن مرضين بثلاثة أعراض. وعند تطبيق قاعدة ثلاثة أعراض على الأقل المُطبقة في الإصدار الأول، تحصل على 6 مجموعات ثلاثية من الأعراض المحتملة التي تُؤخذ في عين الاعتبار.
في قاعدة المعرفة الجديدة بالأعلى، تكون للأمراض الأربعة 6 و8 و5و5 أعراض على التوالي. وبهذا تحصل على 96 مجموعة ثلاثية من الأعراض المحتملة وفي حال التعامل مع مئات أو حتى آلاف الأمراض ستجد أنه من المستحيل إنشاء نظام مثل الموجود في الإصدار الأول.
وكذلك لا يوجد سبب طبي وجيه لقصر التشخيص الطبي على مجموعات ثلاثية من الأعراض. ولذلك، ستجعل منطق التشخيص (Diagnosis Logic) أكثر تنوعًا بحساب عدد الأعراض المطابقة لكل مرض، والسماح للمستخدم بتحديد عدد الأعراض المطابقة التي يجب توافرها في المرض لتضمينه في التشخيص.

اتخاذ القرار القائم على القواعد

لا يحتوي هذا الإصدار على عبارات IF الشرطية المحددة بتعليمات برمجية ثابتة. بعد تحميل مخطط الأعراض من ملف JSON، يبدأ الإصدار في أخذ كل مرض محتمل في الاعتبار باستخدام حلقة التكرار FOR، تتحقق الحلقة من كل عرض على حدة بمقارنته بالأعراض المعروفة للمرض وزيادة العدّاد (Counter) في كل مرة يجد فيها النظام تطابقًا.

لاحظ أن الإصدار الثاني هو نسخة مُعممّة من الإصدار الأول، ومع ذلك يُعد هذا الإصدار أكثر قابلية للتطبيق على نطاق واسع، ويمكن استخدامه كما هو مع أي قاعدة معرفة أخرى بالتنسيق نفسه، حتى لو كانت تشمل الآلاف من الأمراض مع عدد ضخم من الأعراض.
كما يسمح للمستخدم بزيادة أز تقليل عدد القيود على التشخيص بضبط المتغير matching_sympotms_lower_bound ، يمكن ملاحظة ذلك في حالة المريض 1 والمريض2: فعلى الرغم من أنهم يعانيان من الأعراض نفسها، إلا أنه عند ضبط هذا المتغير، ستحصل على تشخيص مختلف تمامًا.
على الرغم من هذه التحسينات إلا أن بعض العيوب لا تزال موجودة في هذا الإصدار، ولا يعد تمثيلاً دقيقًا للتشخيص الطبي الحقيقي.
بإمكانك مراجعة محتوى موضوع “اتخاذ القرار القائم على القواعد” بدايةً من عنوان “الإصدار 2” وحتى نهاية هذا القسم، من خلال الرابط التالي:
الإصدار 3
في الإصدار الثالث ستزيد من ذكاء النظام القائم على القواعد بمنحه إمكانية الوصول إلى نوع مُفصّل من قاعدة المعرفة، هذا النوع الجديد يأخذ بعين الاعتبار الحقيقة الطبية التي تقول: إن بعض الأعراض تكون أكثر شيوعًا من أخرى للمرض نفسه.
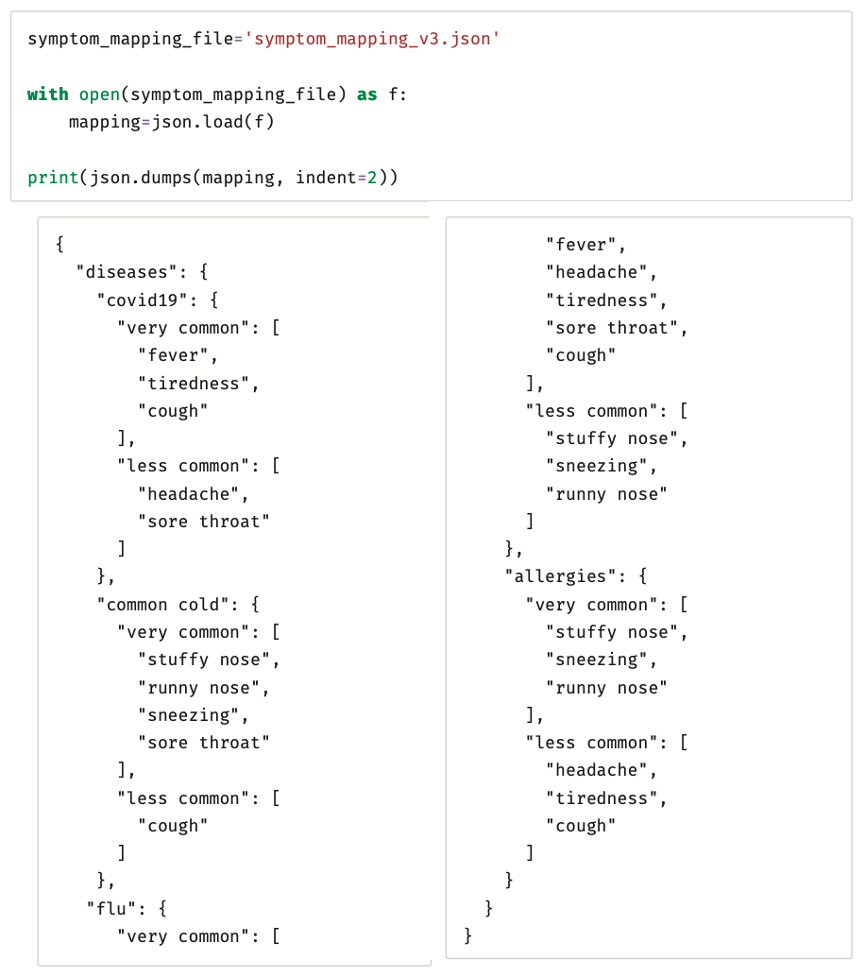
لن يُنظر إلى المنطق الذي يقتصر على عدد الأعراض، وسيُستبدل بدالة تسجيل النقاط التي تُعطي أوزانًا مخصصة للأعراض الأكثر والأقل شيوعًا. ستتوفر للمستخدم كذلك المرونة لتحديد الأوزان التي يراها مناسبة. سيتم تضمين المرض أو الأمراض ذات المجموع الموزون الأعلى في التشخيص.

لكل مرض محتمل في قاعدة المعرفة تحدد هذه الدالة الجديدة الأعراض الأكثر والأقل ظهورًا على المريض، ثم تزيد من درجة المرض وفقًا للأوزان المقابلة، وفي الأخير تُدرج الأمراض ذات الدرجة الأعلى في التشخيص يُمكنك الآن تنفيذ اختبار الدالة مع بعض الأمثلة:

قد تلاحظ على الرغم من أن الأعراض الثلاثة على المريض Headache :1 (الصداع)، وTiredness (الإعياء)، وCough (السعال) تظهر عند الإصابة بكل من Flu (الإنفلونزا)، وCovid19 (كوفيد – 19)، والحساسية إلا أن الظاهر في نتائج التشخيص هي الانفلونزا فقط، هذا لأن جميع الأعراض الثلاثة شائعة جدًا في قاعدة المعرفة، مما يؤدي إلى درجة قصوى قدرها 3، وبالمثل، في ظل معاناة المريض الثاني والثالث من الأعراض نفسها، تؤدي مدخلات الأوزان المختلفة للأعراض الأكثر والأقل شيوعًا إلى تشخيصات مختلفة. وعلى وجه التحديد، ينتج عن استخدام وزن متساوٍ لنوعين من الأعراض إضافة الانفلونزا إلى التشخيص.
بإمكانك مراجعة محتوى موضوع “اتخاذ القرار القائم على القواعد” بدايةً من عنوان “الإصدار 3” وحتى نهاية هذا القسم، من خلال الرابط التالي:
الإصدار 4
يمكن تحسين النظام القائم على القواعد بزيادة كفاءة قاعدة المعرفة وتجربة دوال تسجيل النقاط (Scoring Functions) المختلفة. وعلى الرغم من أن ذلك سيؤدي إلى تحسين النظام، إلا أنه سيطلب الكثير من الوقت والجهد اليدوي. ولحسن الحظ هناك طريقة آلية لبناء نظام مبني على القواعد يكون ذكيًا مما يكفي لتصميم قاعدة معرفة ودالة تسجيل نقاط خاصة به، باستخدام تعلم الآلة.
يُطبق تعلم الآلة القائم على القواعد (Rule-Based Machine Learning) خوارزمية تعلم لتحديد القواعد المفيدة تلقائيًا، بدلاً من الحاجة إلى الإنسان لتطبيق المعرفة والخبرات السابقة في المجال لبناء القواعد وتنظيمها يدويًا.
فبدلاً من قاعدة المعرفة ودالة تسجيل النقاط المصممة يدويًا، تتوقع خوارزمية تعلم الآلة مدخلاً واحدًا فقط وهو مجموعة البيانات التاريخية للحالات المرضية. فالتعلم من البيانات مباشرة يحول دون حدوث المشكلات المرتبطة باكتساب المعرفة الأساسية والتحقق منها.
تتكون كل حالة من بيانات أعراض المريض والتشخيص الطبي الذي يمكن أن يقدمه أي خبير بشري مثل الطبيب. وباستخدام مجموعة بيانات التدريب تتعلم الخوارزمية تلقائيًا كيف تتنبأ بالتشخيص المحتمل لحالة مريض جديد.

في المثال أعلاه، تحتوي مجموعة بيانات على 2000 حالة مرضية، بحيث تتكون كل حالة من 8 أعراض محتملة: Fever (الحمى)، Tiredness (الإعياء)، Headache (الصداع)، Stuffy nose (انسداد الأنف)، Runny nose (رشح الأنف)، Sneezing (العُطاس)، Sore throat (التهاب الحلق).
ترمز كل واحدة من هذه الأعراض في عمود ثنائي منفصل، العدد الثنائي 1 يشير إلى أن المريض يعاني من الأعراض بينما العدد الثنائي 0 يشير إلى أن المريض لا يعاني من الأعراض.
يحتوي العمود الأخير على تشخيص الخبير البشري، وهناك أربعة تشخيصات محتملة:
- Covid19 (كوفيد-19).
- Flu (الانفلونزا).
- Allergies (الحساسية).
- Common Cold (نزلات البرد).
يمكنك التحقق من ذلك باستخدام المقطع البرمجي التالي بلغة بايثون: 
على الرغم من أن هناك العشرات من خوارزميات تعلم الآلة المحتملة التي يمكن استخدامها مع مجموعة من البيانات هذه، إلا أنك ستستخدم تلك التي تتبع المنهجية المستندة على منطق شجرة القرار (Decision Tree)، كما ستستخدم DecisionTreeClassifier (مصنف شجرة القرار) من مكتبة بايثون سكليرن (Sklearn) على وجه التحديد.
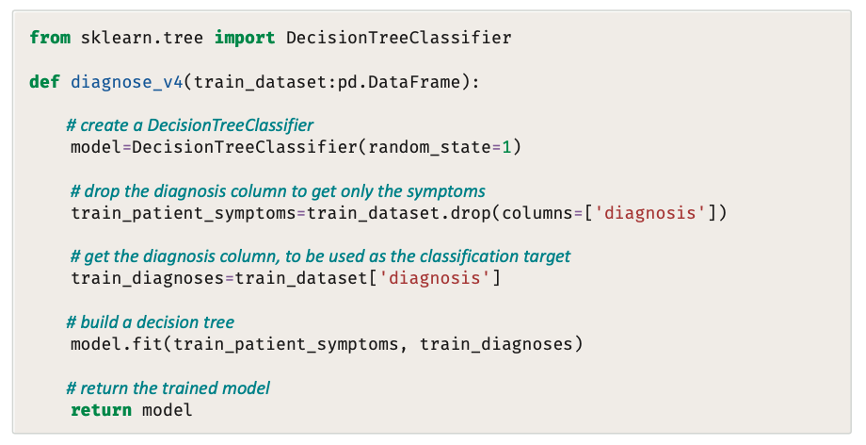
يعد تطبيق البايثون في الاصدار الرابع أقصر وأبسط بكثير من التطبيقات السابقة، فهو ببساطة يقرأ الملف التدريبي ويستخدمه لبناء نموذج شجرة القرار استنادًا إلى العلاقات بين الأعراض والتشخيصات. ومن ثم ينتج نموذجًا مخصصًا.
لاختبار هذا الإصدار بشكل صحيح، ابدأ بتقسيم مجموعة البيانات إلى مجموعتين منفصلتين واحدة للتدريب، وأخرى للاختبار.

لديك الآن 1400 نقطة بيانات ستستخدم لتدريب النموذج و600 نقطة ستُستخدم لاختباره.
ابدأ بتدريب نموذج شجرة القرار وتمثيله:

تستخدم دالة plot_tree() لرسم وعرض شجرة القرار. ولعدم توفر مساحة كافية للعرض سيتم تمثيل المستويين الأولين فقط، يمكن ضبط هذا الرقم بسهولة باستخدام المتغير max_depth.

كل عقدة في الشجرة تمثل مجموعة فرعية من المرضى فعلى سبيل المثال، تُمثل عقدة الجذر إجمالي عدد 1400 مريض في مجموعة بيانات التدريب، من بينهم، 354، و354، و358، و343 شُخِّصوا بـ Allergies (الحساسية)، Common Cold (نزلات البرد)، Covid19 (كوفيد19)، Flu (الإنفلونزا)، على التوالي.


بُنيت الشجرة باستخدام نمط من الأعلى إلى الأسفل عبر التفرع الثنائي (Binary Splits). يستند التفرع الأول إلى ما إذا كان المريض يعاني من الحُمى أم لا، ونظرًا لأن كل خصائص الأعراض ثنائية الأبعاد يكون التحقق a<=0.5صحيحًا إذا لم يكن المريض يعاني من الأمراض.
أما المرضى الذين لا يعانون من الحمى (المسار الأيسر) يتفرعون مرة أخرى بناء على ما إذا كانوا يعانون من ألم التهاب الحلق أم لا.
المرضى الذين لا يعانون من التهاب الحلق يتفرعون بناء على ما إذا كانوا يعانون من رشح الأنف أم لا.
في هذه المرحلة تحتوي العقدة على 526 حالة، تم تشخيص 354، و101، و58، و13 من بينهم الحساسية ونزلات البرد وكوفيد-19، والانفلونزا على التوالي:

يستمر التفرع حتى تحدد الخوارزمية الحالات التي انقسمت بالفعل إلى عقد نقية تمامًا.
العقدة النقية بالكامل تحتوي على الحالات التي لها التشخيص نفسه، قيم مؤشر gini (جيني) المحددة على كل عقدة، تمثل مؤشرات على مقياس جيني وهي صيغة شهيرة تستخدم لتقييم درجة نقاء العقدة.
لاحظ أن
يقيس مؤشر جيني (Gini Index) الشوائب بالعُقدة، وبالتحديد احتمالية تصنيف محتويات العُقدة بصورة خاطئة. يشير انخفاض مُعامِل جيني إلى ارتفاع درجة تأكُد الخوارزمية من التصنيف.
ستَستخدِم الآن شجرة القرار للتنبؤ بالتشخيص الأكثر احتمالاً للمرضى في مجموعة الاختبار.
تُستخدم مجموعة الاختبار لتقييم أداء النموذج تستند طريقة التقييم الدقيقة على ما إذا كان المقصود من المهمة الانحدار (Regression) أم التصنيف (Classification) في مثل مشكلات التصنيف المعروضة هنا، تُستخدم طرائق التقييم الشهيرة مثل: حساب دقة النموذج (Models Accuracy) ومصفوفة الدقة (Confusion Matrix).
- الدقة هي نسبة التنبؤات الصحيحة التي يقوم بها المصنف تحقق دقة عالية قريبة من 100% يعني أن معظم التنبؤات التي يقوم بها المصنف صحيحة.
- مصفوفة الدقة هي جدول يقارن بين القيم الحقيقية (الفعلية) وبين التنبؤات التي يقوم بها المصنف في مجموعة البيانات. يحتوي الجدول هلى صف واحد لكل قيمة صحيحة وعمود واحد لكل قيمة متوقعة. كل مدخل في المصفوفة يمثل عدد الحالات التي لها قيم فعلية ومتوقعة.

ستلاحظ أن شجرة القرار تحقق دقة تصل إلى 81.6% وهذا يعني أنه من بين 600 حالة تم اختبارها شخصت الشجرة 490 منها بشكل صحيح. يمكنك كذلك طباعة مصفوفة الدقة للنموذج لتستعرض بشكل أفضل الأمثلة المصنفة بشكل خاطئ.


الأرقام الواقعة في الخط القُطري (المظللة باللون الوردي) تمثل الحالات المتوقعة بشكل صحيح، أما الأرقام التي تقع خارج الخط القُطري فتمثل أخطاء النموذج.
على سبيل المثال، بالنظر إلى ترتيب التشخيصات الأربعة المحتملة:
- Allergies (الحساسية).
- Common cold (نزلات البرد).
- Covid19 (كوفيد-19).
- Flu (الإنفلونزا).
توضح المصفوفة أن النموذج أخطأ في تصنيف 48 حالة من المصابين بنزلات البرد بأنهم مصابون بالحساسية، كما أخطأت في تصنيف 31 حالة من المصابين بالإنفلونزا بأنهم مصابون بكوفيد-19.
وعلى الرغم من أن النموذج ليس مثاليًا فمن المثير للدهشة أنه قادر على تحقيق مثل هذه الدرجة العالية من الدقة بتعلم مجموعة القواعد الخاصة به، دون الحاجة إلى قاعدة معرفة اُنشأت يدويًا.
بالإضافة، إلى تحقيق مثل هذه الدقة دون محاولة ضبط متغيرات الأداء المتنوعة ل DecisionTreeClassifier(مصنف شجرة القرار).
وبالتالي، يمكن تحسين دقة النموذج لأفضل من ذلك، كما يمكن تحسين النموذج بتجاوز قيود النموذج القائم على القواعد وتجربة أنواع مختلفة من خوارزميات تعلم الآلة.
بإمكانك مراجعة محتوى موضوع “اتخاذ القرار القائم على القواعد” بدايةً من عنوان “الإصدار 4” وحتى نهاية الموضوع، من خلال الرابط التالي:
اختبر تحصيلك لمحتوى الموضوع من خلال الرابط التالي:
الواجب الإلكتروني
إلى هنا يكون قد انتهى موضوع “اتخاذ القرار القائم على القواعد“، لا تنسوا مراجعة أهداف التعلُّم أعلى المقال، وانتظرونا في الموضوع القادم!