التعلم غير الموجه لتحليل الصور | الوحدة الأولى| الدرس الثاني

التعلم غير الموجه لتحليل الصور هو عنوان الدرس الأول من الوحدة الرابعة التي تحمل اسم “التعرُّف على الصور” في الفصل الدراسي الثاني من مقرر “تقنية رقمية 1”.
تعرفنا في الموضوع السابق على رؤية الحاسب وكيفية استخدام التعلم الموجه في تحليل الصور، بينما نتعرف في هذا الموضوع على استخدام التعلم غير الموجه.

التعلم غير الموجه
اقرأ أهداف التعلُّم بعناية، واحرص على مراجعتها، والتأكُّد من تحصيلها؛ لتحقيق أكبر استفادة وفهم للموضوع.
أهداف التعلُّم
- فهم محتوى الصور.
- تحميل الصور ومعالجتها أوليًا باستخدام لغة بايثون.
- التجميع من دون هندسة الخصائص باستخدام لغة بايثون.
- التجميع بانتقاء الخصائص باستخدام لغة بايثون.
- التجميع باستخدام الشبكات العصبية باستخدام لغة بايثون.
إذا كنت مهتمًا بمعرفة المزيد عن التعلُّم الموجه والتعلم غير الموجه، يمكنك قراءة المقال التالي:
هيا لنبدأ!
فهم محتوى الصور (Understanding Image Content) | التعلم غير الموجه
في سياق رؤية الحاسب، يُستخدَم التعلم غير الموجه في مجموعة متنوعة من المهام، مثل:
- تقطيع أو تجزئة الصورة (Image Segmentation).
- تقطيع الفيديو (Video Segmentation).
- اكتشاف العناصر الشاذة (Anomaly Detection).
- البحث عن الصورة (Image Search).

التعلم غير الموجه

وتعتبر الأخيرة من الاستخدامات الرئيسة للتعلم غير الموجه، حيث تتضمن البحث في قاعدة بيانات كبيرة من الصور للعثور على صور مشابهة للصورة المطلوبة.

خطوات بناء محرك بحث لبيانات صورة؟
- تحديد دالة التشابه (Similarity Function)، والتي تقوم بتقييم التشابه بين الصورتين بناءً على خصائصهما المرئية، مثل: الحدود، النقش، الشكل.
- بمجرد إرسال المستخدِم صورة جديدة للاستعلام عنها، يقوم محرك البحث بالاطلاع على جميع الصور الموجودة بقاعدة البيانات، ويعثر على الصور التي بها أعلى درجات التشابه، ويظهرها للمستخدِم.
هل هناك طريقة بديلة؟!
نعم، وتتمثل في..
- استخدام دالة التشابه لفصل الصور في عناقيد، يتكون كل عنقود من صور متشابهة بصريًا مع بعضها، ثم يتم تمثيل كل عنقود من خلال بؤرة تجميع (Centroid)، وهي صورة تقع في مركز العنقود وتمتلك أقل اختلاف مع الصور الأخرى في العنقود.
- بمجرد أن يرسل المستخدِم صورة للاستعلام عنها، فإن محرك البحث سينتقل إلى العناقيد، ويختار العنقود الذي تكون بؤرة تجميعه أكثر تشابهًا مع الصورة المطلوبة من المستخدم؛ لتظهر له صور العنقود المحددة.
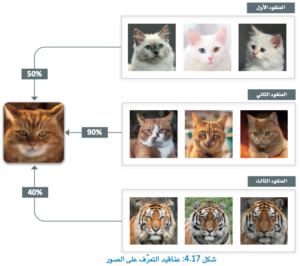
التعلم غير الموجه
في المثال السابق، تحتوي صورة البحث على تشابه بنسب: 40% و50% و90% مع بؤر التجميع للعناقيد (الصورة في مركز كل عنقود)،
ويفترض أن تكون نسب التشابه بين 0% و100%، وحصل العنقود الثاني على أعلى نسب تشابه،
حيث يشتمل على قطط من نفس سلالة ولون القطة المُحدَّدة.
أما العنقود الأول (50%) فيتضمن قطط تختلف ألوانها مع صورة البحث، بينما العنقود الثالث (40%) فيتضمن حيوان أخر وهو النمر ولكن له نفس نمط ألوان صورة البحث.
تحميل الصور ومعالجتها أوليًا (Loading and Preprocessing Images)
يستورد المقطع البرمجي التالي المكتبات التي سيتم استخدامها لتحميل الصور ومعالجتها أوليًا:

التعلم غير الموجه
تقرأ الدالة التالية صورة مجموعة بيانات وجوه الحيوانات (LHI-Animal-Faces) من مجلد_المدخلات (input_folder) الخاص بها، وتقوم بتعديل حجم كل منها بحيث تكون لها نفس أبعاد الطول والعرض.
ثم بتحسين دالة resize_images ( ) تسمح للمُستخدِم بتحديد قائمة الحيوانات التي تؤخذ في الاعتبار،
كما أنها تستخدِم سطرًا واحدًا من المقطع البرمجي بلغة بايثون؛ لتقرأ كل صورة وتعدِّل حجمها وتخزِّنها.

البيانات غير المنظَّمة (Unstructured Data) متنوّعة، ومن الممكن أن تحتاج إلى الكثير من الوقت والموارد الحاسوبية عند معالجتها عن طريق أساليب تعلُّم عميقة ومعقدة، ولتقليل الوقت الحسابي يتم تطبيق دالة resize_images_v2 ( ) على مجموعة فرعية من الصور من فئات الحيوانات.
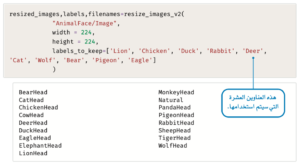
بإمكانك استخدام تعديل المتغيِّر العناوين_المحتفظ بها (labels_to_keep)؛ للتركيز على فئات معينة.
لاحظ
أبعاد الصور هي 224 * 224 بدلًا من 100 * 100 الذي تم استخدامه في الموضوع السابق،
لأن أحد طرائق التجميع القائمة على التعلُّم العميق في هذا الموضوع تعتمد على الأبعاد 224 * 224؛
لضمان حق وصول جميع الطرائق للمُدخَلات نفسها.
لا حظ أيضًا
القوائم الأصلية: الصور_المعدَّل حجمها (resized_images)، والعناوين (labels)، وأسماء الملفات (filenames) تشتمل على الصور المنتمية لكل فئة مجمعة معًا.
على سبيل المثال: تظهر جميع صور الأسد (Lion) معًا في بداية القائمة المعدَّل حجمها، وقد يضلل ذلك العديد من الخوارزميات؛
خاصةً في مجال رؤية الحاسب، وطالما أنه من الممكن فهرسة الصور عشوائيًا لكل قائمة من القوائم الثلاثة،
فمن المهم استخدام الترتيب العشوائي نفسه لهذه القوائم، وبخلاف ذلك مستحيل العثور على العنوان الصحيح لصورة معيَّنة أو اسم الملف الصحيح لها.
تم إجراء إعادة الترتيب (Shuffling) في الموضوع السابق، باستخدام دالة train_test_split ( )،
وبما أنها غير قابلة للتطبيق على مهام التجميع؛ سنستخدم المقطع البرمجي التالي:

التعلم غير الموجه
الخطوة التالية هي تحويل قائمتي الصور_المعدَّل حجمها (resized_images) والعناوين (labels) إلى مصفوفات numpy، ويتم استخدام الاسمان المُتغيِّران (X, Y) لتمثيل البيانات والعناوين.

يتبين من الصورة السابقة أن البيانات تشتمل على 1,085 صورة، كل صورة بأبعاد 224 * 224، وذات 3 قنوات ألوان RGB.
قم بمراجعة الجزء السابق من موضوع التعلم غير الموجه لتحليل الصور من خلال الرابط التالي:
التجميع بدون هندسة الخصائص (Clustering without Feature Engineering)
تُركِّز محاولة التجميع الأولى على القيام بتسطيح الصور؛ لتحويل كلٍ منها إلى متَّجَه أحادي البُعد أرقامه 224 * 224 * 3 = 150,528 رقمًا،
وذلك كما تتطلب معظم خوارزميات التجميع هذا النوع من التنسيق المتَّجَهي.
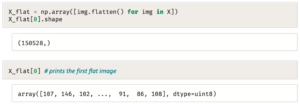
لاحظ
كل قيمة عددية في هذا التنسيق المسطَّح ذات قيمة ألوان RGB تتراوح بين 0 و255.
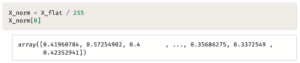
وكما تعلمنا في الموضوع السابق فإن التحجيم القياسي والتسوية يؤديان إلى تحسين نتائج بعض خوارزميات التعلُّم الآلي.
من الممكن الآن تصوير البيانات بصريًا باستخدام أداة TSNEVisualizer من مكتبة yellowbrick،
والتي يتم استخدامها كذلك لتصوير العناقيد بصريًا في البيانات النصية.
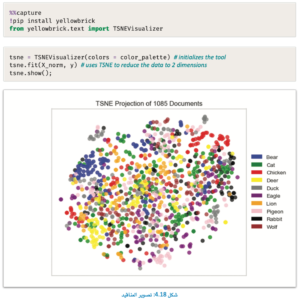
التعلم غير الموجه
يظهر التصوير التمهيدي بخلاف المتوقع، حيث يبدو أن فئات الحيوانات المختلفة مختلطة ببعضها،
دون تمييز واضح، ودون عناقيد واضحة، ويدل ذلك على أن مجرد القيام بتسطيح بيانات الصور الأصلية من المحتمل ألا يؤدي إلى نتائج عالية الجودة.
لذلك..
سنستخدم خوارزمية التجميع التكتلي (Agglomerative Clustering)؛ لتجميع البيانات في متغيِّر X_norm.
يستورد المقطع البرمجي التالي مجموعة الأدوات المطلوبة، ويصوِّر الرسم الشجري لمجموعة البيانات.
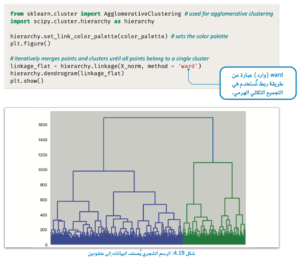
التعلم غير الموجه
يوضح الرسم الشجري عنقودين كبيرين من الممكن تقسيمهما إلى عناقيد أصغر؛ لذلك يستخدم المقطع البرمجي التالي أداة التجميع التكتلي (Agglomerative Clustering)؛
لإنشاء 10 عناقيد، وهو العدد الفعلي للعناقيد في مجموعة البيانات.

وأخيرًا، نستخدِم مؤشرات: التجانس (Homogeneity)، والاكتمال (Completeness)، وراند المُعدَّل (Adjusted Rand)؛ لتقييم جودة العناقيد الناتجة.

التجميع بانتقاء الخصائص (Clustering with Feature Selection)
تناولنا في الموضوع السابق استخدام تحويل المخطَّط التكراري للتدرجات الموجَّهة (HOG) لتحويل بيانات الصور إلى صيغة أكثر دلالة يؤدي؛
مما يؤدي إلى إنجاز أعلى بشكل ملحوظ في تصنيف الصور؛ لذلك سنطبق التحويل نفسه ونتتبع إمكانية تحسين نتائج مهام تجميع الصور.

التعلم غير الموجه
يكشف شكل البيانات المحوَّلة أن كل صورة يتم تمثيلها على هيئة متَّجَه بقيمة عددية، هي: 54,756.
يستخدِم المقطع البرمجي التالي أداة TSNEVisualizer لتصوير التنسيق الجديد.
![]()

يعتبر التصوير السابق أكثر مصداقية من الذي تم إنتاجه للبيانات المحوَّلة، وبالرغم من وجود بعض الشوائب،
إلا أن الشكل يُظهِر عناقيد واضحة ومفصولة جيدًا، ويمكنك الآن حساب الرسم الشجري لمجموعة البيانات.
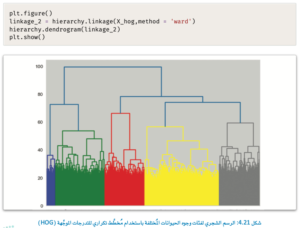
التعلم غير الموجه
يقترح الرسم الشجري 5 عناقيد، وهو نصف العدد الصحيح (10 عناقيد).
يتبنى المقطع البرمجي التالي هذا الاقتراح، ويطبِّق أداة التجميع التكتلي، كما يُظهِر نتائج المؤشرات الثلاثة.

بالرغم من أن عدد العناقيد التي تم استخدامها أقل بقليل من العديد الصحيح؛ إلا أن النتائج أفضل بكثير من النتائج التي ظهرت عند استخدام الرقم الصحيح على البيانات غير المحوَّلة.
ويوضح ذلك ذكاء التحويل بواسطة HOG، ويثبت أنه يمكن يؤدي إلى تحسينات مميزة في الأداء سواء في مهام التعلم الموجه أو التعلم غير الموجه في رؤية الحاسب.
لإكمال التحليل يقوم المقطع البرمجي التالي بإعادة تجميع البيانات المحوَّلة بالعدد الصحيح للعناقيد.
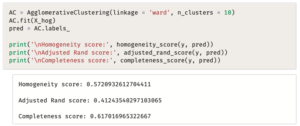
وكما هو المتوقع، زادت قيم المؤشرات.
يدل ذلك على أن الخوارزمية تعمل بشكل أفضل فيما يتعلق بـ:
- وضع الحيوانات التي تنتمي لفئة واحدة في العنقود نفسه.
- إنشاء عناقيد نقية (Pure) تتكون في الغالب من فئة الحيوان نفس.
قم بمراجعة الجزء السابق من موضوع التعلم غير الموجه لتحليل الصور بدايةً من عنوان “التجميع بدون هندسة الخصائص وحتى نهاية هذا القسم من خلال الرابط التالي:
التجميع باستخدام الشبكات العصبية (Clustering Using Neural Networks) | التعلم غير الموجه
الشبكات العصبية العميقة ذات الطبقات المتعددة تعتبر أحدث استخدام لنماذج التعلم العميق، وثورة في مجال تجميع الصور عن طريق توفير خوارزميات عالية الدقة، ويمكنها تجميع الصور المتشابهة معًا تلقائيًا دون الحاجة إلى هندسة الخصائص.
تعتمد العديد من الطرائق التقليدية لتجميع الصور على خاصية المستخرَجات (Extractors) لاستخراج معلومات ذات مغزى من صورة ما، واستخدام هذه المعلومات لتجميع الصور،
لكن تحتاج هذه العملية عادةً وقتًا طويلًا وتتطلب خبرة في المجال لتصميم خاصية المستخرَجات بخصائص فعَّالة؛ بالرغم من ذلك فإن خاصية الواصِفات (Descriptors)،
مثل: تحويل المخطَّط التكراري للتدرجات الموجَّهة يمكنها تحسين النتائج، إلا أنها بعيدة كل البعد عن الكمال، وبالطبع يوجد مجال للتحسين.
من ناحية أخرى، يتمتع التعلم العميق بالقدرة على تعلُّم تمثيلات الخصائص من البيانات الخام تلقائيًا،
ويتيح ذلك لطرائق التعلُّم العميق معرفة الخصائص شديدة التمايز التي تلتقط الأنماط الهامة وراء البيانات؛
مما يؤدي إلى تجميع أكثر دقة وقوة، ولتحقيق ذلك نستخدم عدة طبقات مختلفة في الشبكة العصبية، ومنها:
- الطبقات الكثيفة (Dense Layers).
- طبقات التجميع (Pooling Layers).
- طبقات الإقصاء (Dropout Layers).

التعلم غير الموجه


تذكَّر
في الشبكة العصبية في الدرس الأول من الوحدة الثالثة، تم استخدام طبقة مخفية مكونة من 300 خلية عصبية من نموذج الكلمة إلى المُتَّجَه (Word2Vec)؛
لتمثيل كل كلمة، وفي تلك الحالة تم تدريب نموذج Word2Vec مسبقًا على مجموعة بيانات كبيرة جدًا تحتوي على ملايين الأخبار من أخبار قوقل (Google News).
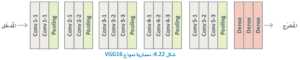
تعتبر نماذج الشبكات العصبية المدرَّبة مسبقًا شائعة أيضًا في رؤية الحاسب، ومن الأمثلة على ذلك نموذج VGG16 الذي يشيع استخدامه في مهام التعرُّف على الصور،
ويتبع ذلك النموذج معمارية عميقة قائمة على الشبكات العصبية الترشيحية على 16 طبقة، ويُعدُّ نموذجًا موجَّهًا تم تدريبه على مجموعة بيانات كبيرة من الصور المُعنونة تسمى شبكة الصور (ImageNet)،
ومع ذلك، تتكون مجموعة بيانات التدريب الخاصة بنموذج VGG16 من ملايين الصور ومئات العناوين المختلفة؛ مما يُحسِّن بشكل كبير من قدرة النموذج على فهم الأجزاء المختلفة من الصورة.
وعلى غرار الشبكة العصبية الترشيحية البسيطة في الصورة التالية، يتم استخدام نموذج VGG16 أيضًا طبقة كثيفة نهائية تضم 4096 خلية عصبية لتمثيل كل صورة قبل إدخالها في طبقة المُخرَج (Output Layer).
وعلى الرغم من أن نموذج VGG16 تم تصميمه في الأصل لتصنيف الصور، تعلَّم كيفية تكييفه لتجميع الصور:
- حمِّل النموذج VGG16 الذي تم تدريبه مسبقًا.
- احذف طبقة المخرَج من النموذج، فذلك يجعل الطبقة الأخيرة الكثيفة هي طبقة المخرَج الجديدة.
- استخدم النموذج المقتطع (Truncated Model) – النموذج السابق الذي اقتُطعت الطبقة الأخيرة م –؛ لتحويل كل صورة في مجموعة بيانات وجوه الحيوانات (Animal Faces) إلى متَّجَه عددي له 4096 قيمة.
- استخدم التجميع التكتلي؛ لتجميع المُتَّجَهات الناتجة عن ذلك.
التعلم غير الموجه
من الممكن استخدام مكتبتا TensorFlow وKeras للوصول إلى نموذج VGG16 واقتطاعه،
وتتمثَّل الخطوة الأولى في استيراد جميع الأدوات المطلوبة.

المقطع البرمجي التالي يُطبِّق المعالجة الأولية الأساسية نفسها التي يتطلبها نموذج VGG16،
مثل: تحجيم RGB؛ لتكون بين 0 و1:
![]()
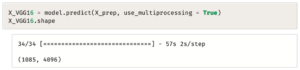
لاحظ أن
شكل البيانات يظل كما هو، أي 1085 صورة، لكل صورة منها أبعادها 224 * 224، و3 قنوات ألوان RGB، وبعد ذلك من الممكن استخدام النموذج المقتطع لتحويل كل صورة إلى متَّجَه مكوَّن من 4,096 عدد.
التعلم غير الموجه
يتم ضبط متغيِّر المعالجة المتعددة تفعيل المعالجة المتعددة (multiprocessing=True)؛
لتسريع العملية من خلال حساب المُتَّجَهات للصورة المُتعدّدة بالتوازي،
وقبل إكمال خطوة التجميع يتم استخدام المقطع البرمجي التالي لتصوير البيانات المتَّجَهة (Vectorized Date).
![]()

التعلم غير الموجه
تبدو النتائج مذهلة؛ لأن التصوير الجديد يكشف عناقيد مفصولة عن بعضها بوضوح وتكاد تكون كاملة،
كما أن الفصل هنا أفضل بكثير من الفصل الذي كان في البيانات التي تم تحويلها بواسطة HOG.
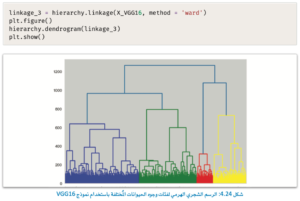
يقترح الرسم الشجري 4 عناقيد، وفي هذه الحالة يُمكِن للممارس تجاهل الاقتراح، واتّباع التصوير السابق بدلًا منع، والذي يُبيِّن بوضوح وجود 10 عناقيد.
يستخدِم المقطع البرمجي التالي التجميع التكتلي، ويوضح قيم المؤشرات لكل من العناقيد الأربعة والعناقيد العشرة.
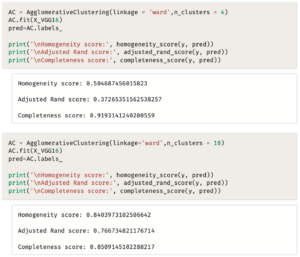
أثبتت النتائج صحة الأدلة التي قدمها التصوير، وتؤدي التحولات التي أنتجها نموذج VGG16 إلى نتائج مذهلة لكل من العناقيد الأربعة والعناقيد العشرة.
في الواقع، ظهرت نتائج شبه مثالية لجميع المؤشرات الثلاثة عند استخدام 10 عناقيد؛
مما يثبت أن النتائج غالبًا تتوافق تمامًا مع فئات الحيوانات في مجموعة البيانات.
يعتبر نموذج VGG16 من أقدم نماذج الشبكات العصبية الترشيحية عالية الذكاء المدرَّبة مسبقًا لغرض استخدامها في تطبيقات رؤية الحاسب،
ومع ذلك تم نشر العديد من نماذج الشبكات العصبية الترشيحية الذكية الأخرى المدرَّبة مسبقًا والتي تجاوز أداؤها نموذج VGG16.
قم بمراجعة القسم السابق من موضوع التعلم غير الموجه لتحليل الصور بعنوان “التجميع باستخدام الشبكات العصبية” من خلال الرابط التالي:
اختبر تحصيلك لمحتوى الموضوع من خلال الرابط التالي:
الواجب الإلكتروني
إلى هنا يكون قد انتهى موضوع “التعلم غير الموجه لتحليل الصور”، لا تنسوا مراجعة نواتج التعلُّم أعلى المقال، وانتظرونا في الموضوع القادم!