توليد البيانات المرئية | الوحدة الأولى | الدرس الثالث

توليد البيانات المرئية هو عنوان الدرس الأول من الوحدة الرابعة التي تحمل اسم “التعرُّف على الصور” في الفصل الدراسي الثاني من مقرر “تقنية رقمية 1”.
تعرفنا في المواضيع السابقة من هذه الوحدة على كيفية تحليل صور عن طريق استخدام التعلم الموجه والتعلم غير الموجه، بينما نتعرف في هذا الموضوع على كيفية توليد البيانات المرئية باستخدام الذكاء الاصطناعي وغيره من التقنيات.

اقرأ أهداف التعلُّم جيدًا، واحرص على مراجعتها وتحصيلها بعد الانتهاء من دراسة الموضوع؛ للتأكد من تحقيق أكبر استفادة ممكنة.
أهداف التعلُّم
- استخدام منصة قوقل كولاب لتوليد الصور.
- معرفة معمارية الشبكة التوليدية التنافسية.
- توليد الصور بالانتشار المستقر.
- توليد الصورة من نصّ.
- توليد صورة من صورة من خلال الاسترشاد بنص.
- رسم صورة من خلال الاسترشاد بنصّ.
هيا لنبدأ!
استخدام الذكاء الاصطناعي في توليد الصور (Using AI to Generate Images)
يُركِّز مجال توليد الصور (Image Generation) على إنشاء صورة جديدة، كما أن له تاريخ طويل يعود إلى الخمسينات والستينات من القرن العشرين، عندما بدأ الباحثون إجراء تجارب على معادلات رياضية لإنشاء الصور لأول مرة.
في العصر الحالي، نما هذا المجال ليشمل مجموعة واسعة من التقنيات، ويُعدُّ استخدام الفراكتلات (Fractals) من أقدم وأشهر تقنيات إنشاء الصور.
- الفراكتل
هو شكل أو نمط هندسي مشابه لذاته؛ مما يعني أنه يبدو متشابهًا عند تكبيره بمقاييس مختلفة، وأشهر فراكتل هو الذي يضم مجموعة ماندلبروت (Mandelbort).

في أواخر القرن العشرين، بدأ الباحثون في استكشاف أساليب أكثر تقدمًا لتوليد الصور مثل الشبكات العصبية، نستعرض أهمها في السطور التالية.
توليد الصور والمواد الحاسوبية (Image Generation and Computational Resources)
إنشاء الصور مهمة مُكلِّفة من الناحية الحاسوبية؛ لأنها:
- تتضمن استخدام خوارزميات معقدة تتطلب قدرات عالية من قوة المعالجة.
- تتضمن عادةً معالجة كميات كبيرة من البيانات، مثل: نماذج ثلاثية الأبعاد، والنقوش، ومعلومات الإضاءة.
يُعدُّ استخدام وحدات معالجة الرسومات (Graphics Processing Units – GPUs) أحد التقنيات الرئيسة المُستخدمة لتسريع توليد الصور.

فعلى عكس وحدات المعالجة المركزية (Central Processing Unit – CPU) التقليدية المصممة للتعامل مع مجموعة واسعة من المهام؛ فإن وحدات معالجة الرسومات تم تحسينها لتتناسب مع أنواع العمليات الحسابية المطلوبة لمعالجة الصور والمهام الأخرى المتعلقة بالرسومات؛ مما يجعلها أكثر كفاءة في التعامل مع كميات كبيرة من البيانات وإجراء عمليات حسابية معقدة.
ستتعلم في هذا الموضوع كيفية استخدام منصة قوقل كولاب (Google Colab) للوصول إلى بنية تحتية قوية قائمة على وحدة معالجة الرسومات دون أي تكلفة، وذلك باستخدام حساب عادي على قوقل.
تعريف هام
قوقل كولاب هي منصة مجانية تعتمد على التقنية السحابية، وتتيح للمستخدمين كتابة المقاطع البرمجية، وتنفيذها، وإجراء التجارب، وتدريب النماذج في بيئة مفكرة جوبيتر (Jupyter Notebook).

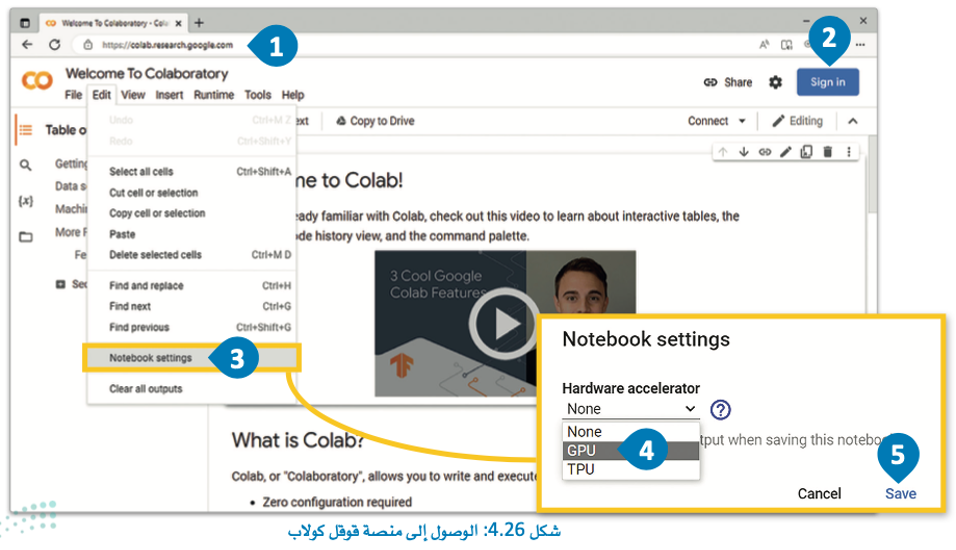

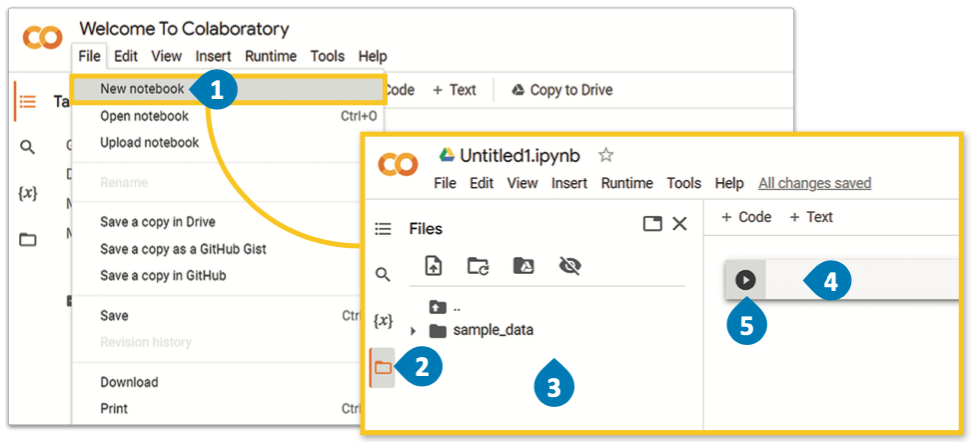
تعمل بيئة قوقل كولاب بشكل مُشابه لعمل مفكرة جوبيتر، لاحظ جملة Hello World بالمثال التالي:
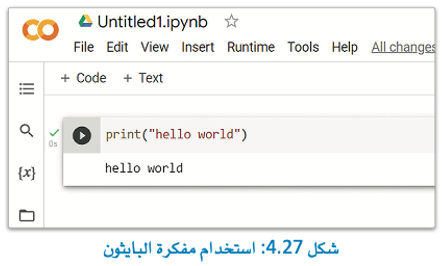
لاحظ أن
خوارزميات توليد الصور (Image Generation) التي وصفناها مصممة بطريقة تجعلها إبداعية، وبالتالي فهي ليست ثابتة؛ مما يعني أنه من غير المضمون أن تقوم دائمًا بتوليد الصورة نفسها للمُدخَلات نفسها.
توليد الصور بالشبكة التوليدية التنافسية (Generating Images with Generative Adversarial Networks – GANs)
الشبكة التوليدية التنافسية هي فئة من النماذج التوليدية التي تتكون من مكونين رئيسين، هما: المولِّد (Generator) والمميِّز (Discriminator)، حيث يقوم المولِّد بتوليد صور زائفة، بينما يحاول الممِّيز تمييز الصورة المولَّدة من الصور الحقيقية.
يتم تدريب هذان المكونان تدريبيًا تنافسيًا، إذ يحاول المولِّد أن يخدع المميِّز، ويحاول المميِّز أن يصبح أفضل في اكتشاف الصور الزائفة.
المزايا
- القدرة على توليد صور عالية الجودة وواقعية يصعب تمييزها عن الصور الحقيقية.
القيود
- عدم التقارب (Non-convergence) أو بعبارة أخرى، فشل شبكتي المولِّد والمميِّز في التحسن مع مرور الوقت.
- نقص التنوع (Mode Collapse) في المُخرَجات، حيث ينتج النموذج نفس المُخرَجات المتشابهة مرارًا وتكرارًا بغض النظر عن المُدخَلات.

توليد الصور بالانتشار المستقر (Generating Images with Stable Diffusion)
الانتشار المستقر هو نموذج تعلُّم عميق لتوليد صورة من نصّ، ويتكون من مكونين رئيسين، هما: مُرمِّز النصّ (Text Encoder)، ومفكِّك الترميز المرئي (Visual Decoder)، ويتم تدريبهم على معًا على مجموعة بيانات مكونة من بيانات نصوص وبيانات صور مقترنة ببعضها؛ حيث يقترن كل مُدخَل نصِّي بصورة مقابلة أو أكثر.
هيا لنتعرف على كيفية عمل الانتشار المستقر لتوليد الصور من خلال النقاط التالية:
- مُرمِّز النص هو شبكة عصبية تأخذ مدخلات نصية مثل: جملة أو فقرة وتحولها إلى تضمين (Embedding).
وما هو التضمين؟
هو متَّجَه عددي له عدد ثابت من القيم، ويلتقط تمثيل التضمين هذا معنى النصّ المُدخَل.
يتم استخدام نهج مشابه في نموذج الكلمة إلى المُتَّجَه (Word2Vec) ونموذج ترميز الجُمل ثنائية الاتجاه من المحولات (SBERT)، حيث يولدان تضمينات للكلمات والجُمل الفردية على الترتيب.
- يُمرَّر بعد ذلك تضمين النص (Text Embedding) الذي أنشأه المُرمِّز عبر مُفكِّك الترميز المرئي لتوليد صورة.
وما هو مفكك الترميز المرئي؟!
هو أيضًا نوع من الشبكات العصبية ويتم تنفيذه عادةً باستخدام شبكة عصبية ترشيحية (CNN) أو معمارية مشابهة.
- تقارن الصورة المولَّدة بالصورة الحقيقية الموجودة في مجموعة البيانات، ويُستخدم الفرق بينهما لحساب الخسارة (Loss)، ثم تُستخدم الخسارة لتحديث متغيِّرات مُرمِّز النصّ ومفكِّك الترميز المرئي؛ لتقليل الاختلاف بين الصور المولَّدة والحقيقية.

حقَّق كل من نموذج الشبكة التوليدية التنافسية ونموذج الانتشار المستقر نتائج مبهرة في مجال توليد الصور، ويُركِّز الجزء المتبقي من هذا الموضوع على تقديم أمثلة عملية بلغة بايثون على أحدث ما توصلت إليه التقنية وهو النهج القائم على الانتشار (Diffusion-Based).
كما ذكرنا من قبل، فإن توليد الصور مهمة مكلفة حاسوبيًا، ولذلك نوصيك بأن تطبق جميع أمثلة بايثون على نظام Google Colab الأساسي أو أي بنية أساسية مختلفة تدعمها وحدة معالجة رسومات يكون لديك حق الوصول إليها.
نستخدم في هذا الموضوع مكتبة diffusers وهي حاليًا أفضل مكتبة مفتوحة المصدر للنماذج القائمة على الانتشار، ويتم تثبيتها عن طريق المقطع البرمجي التالي، وكذلك بعض المكتبات الإضافية المطلوبة.

يمكنك مراجعة الموضوع حتى نهاية هذا القسم بعنوان “توليد الصور بالانتشار المستقر” من خلال الرابط التالي:
توليد الصورة من نصّ (Text-to-Image Generation)
نستعرض في هذا القسم الطريقة التي يُمكن بها استخدام مكتبة diffusers لتوليد صور تعتمد على التوجيه النصيّ الذي يقدمه المستخدم، ونستخدم في الأمثلة التالية نموذج الانتشار-المستقر-الإصدار 4-1) stable-diffusion-v1-4، وهو نموذج شائع لتوليد صورة من نصّ.

يستجيب النموذج للتوجيه A photo of a white lion in the jungle (صورة أسد أبيض في الغابة) بصورة مبهرة وواقعية، ويُعدُّ التجريب باستخدام التوجيهات الإبداعية هو أفضل طريقة لاكتساب الخبرة وفهم قدرات هذا النهج ونقاط ضعفه.

معلومة
معمارية أجهزة الحاسب الموحد (Compute Unified Device Architecture – CUDA) هي منصة حوسبة موازية تتيح استخدام وحدات معالجة الرسومات (GPUs).
يضيف التوجيه (Prompt) في المقطع التالي بُعدًا إضافيًا لعملية التوليد، إذ يوجِّه برسم أسد أبيض بطريقة بيكاسو (Pablo Picasso) أحد أشهر الرسامين في القرن العشرين.

ومرة أخرى، النتائج مبهرة وتؤكد على الإبداع في عملية الانتشار المستقر، فالصورة الناتجة عن العملية هي في واقع صورة أسد أبيض، ويؤدي التوجيه الجديد إلى صورة تُشبه الرسم بدلًا من أن تُشبه الصور الفوتوغرافية، بالإضافية لذلك، فإن أسلوب اللوحة يُشبه بالفعل أسلوب بابلو بيكاسو.

توليد صورة من صورة من خلال الاسترشاد بنصّ (Image-to-Image Generation with Text Guidance)
يستخدِم المثال التالي مكتبة diffusers لتوليد صورة بناءً على مُدخَلين، هما:
- صورة موجودة تعمل كأساس للصورة الجديدة التي سيتم إنشاؤها.
- توجيه نصيّ يصف الشكل الذي يجب أن تبدو عليه الصورة المنتَجة.
بما أن مهمة تحويل النص إلى صورة في القسم السابق كانت محدودة فقط بالتوجيه النصي، فيجب أن تضمن المهمة الجديدة أن تكون الصورة الجديدة مشابهة للصورة الأصلية، وممثلة بشكلٍ دقيق للوصف الوارد في التوجيه النصي.
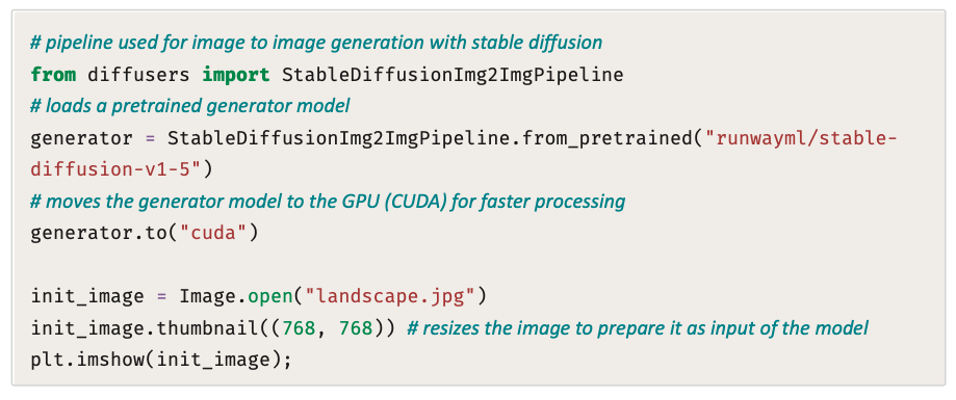
المثال الموجود في الصورتين التاليتين النموذج المُدرَّب مُسبقًا stable-diffusion-v1-4 المناسب لتوليد صورة من صورة إلى جانب التوجيه النصيّ.



في الواقع، يولِّد النموذج صورة مستجيبة للتوجيه النصيّ ومشابهة بصريًا للصورة الأصلية، ويُستخدم مُتغيِّر القوة (strength) للتحكم في الاختلاف البصري بين الصورة الأصلية والصورة الجديدة.
يتخذ مُتغيِّر القوة قيمًا بين 0 و1، وتسمح القيم الأعلى للنموذج بأن يكون أكثر مرونة وأقل تقيُّدًا بالصورة الأصلية.
على سبيل المثال، يُستخدَم المقطع البرمجي التالي لنفس التوجيه (prompt) من خلال ضبط المُتغيِّر strength = 1.


تؤكد الصورة التالية أن زيادة قيمة مُتغيِّر القوة تؤدي إلى شكل بصري أفضل بالإرشاد الوارد في التوجيه النصيّ، ولكنه كذلك أقل تشابهًا إلى حد كبير مع الصورة المُدخلة.
لاحظ المقطع البرمجي التالي، ومخرجه في شكل 4.34.


ويُستخدَم المقطع البرمجي التالي لتحويل هذه الصورة إلى صورة نمر (tiger):

تتقيد المحاولة الأولى بقيمة المُتغيِّر strength؛ مما أدى إلى صورة تبدو وكأنها مزيج بين النمر والقطة الموجودة في الصورة الأصلية، كما هو موضح في الشكل 4.35.
تدل الصورة الجديدة على أن الخوارزمية لم تكن لديها القوة الكافية لتحويل وجه القطة تحويلًا صحيحًا إلى وجه نمر، وتظل الخلفية مشابهة جدًا لخلفية الصورة الأصلية.

بعد ذلك، تتم زيادة المُتغيِّر strength للسماح للنموذج بالابتعاد عن الصورة الأصلية والاقتراب أكثر من التوجيه النصيّ.

لاحظ أن
الصورة الجديدة المعروضة هي صورة نمر، ولكن البيئة المحيطة بالحيوان ووضعية جلوسه وزواياه تظل شديدة الشبه بالصورة الأصلية، ويدُل ذلك على أن النموذج ما زال واعيًا بالصورة الأصلية وحاول المحافظة على عناصر كان لابد ألا تتغير؛ حتى يقترب من التوجيه النصيّ.

يمكنك مراجعة هذا الجزء من الموضوع بدايةً من عنوان “توليد الصورة من النص” وحتى نهاية هذا القسم من خلال الرابط التالي:
رسم صورة بالاسترشاد بنصّ (Text-Guided Image-Inpainting)
يُركِّز المثال التالي على استخدام نموذج الانتشار المستقر لاستبدال شكل بصري يصفه توجيه نصي جديد بأجزاء مُحدَّدة من صورة معيَّنة، ويُستخدم لهذا الغرض النموذج المُدرَّب مُسبقًا رسم_الانتشار_المستقر (stable-diffusion-inpainting).
يقوم المقطع البرمجي التالي بتحميل صورة قطة على مقعد، وهناك قناع (Mask) يعزل الأجزاء المُحدَّدة من الصورة التي تغطيها القطة:


القناع (Mask) هو صورة بسيطة بالأبيض والأسود لها نفس أبعاد الصورة الأصلية بالضبط، والأجزاء التي يتم استبدالها في الصورة الجديدة تُميَّز باللون الأبيض، في حين أن باقي الأجزاء الأخرى من القناع سوداء.
بعد ذلك، يتم تحميل النموذج المُدرَّب مُسبقًا، ويتم إنشاء توجيه (prompt) لكي توضع صورة رائد فضاء مكان القطة الموجودة بالصورة الأصلية.

يظهر نجاح التوجيه النصي الجديد في تكوين صورة واقعية للغاية لرائد الفضاء الذي تم وضعه مكان القطة التي كانت موجودة بالصورة الأصلية، كما يمتزج بسلاسة مع عناصر الخلفية والإضاءة.

في الواقع، حتى لو كان القناع أبسط وأقل؛ يُمكِن إنتاج بديل واقعي، لاحظ المثال التالي:


يغطي القناع في هذا المثال جهاز الحاسب المحمول، ثم يُستخدم التوجيه التالي والمقطع البرمجي؛ ليتم وضع صورة كتاب مكان جهاز الحاسب الموجود بالصورة الأصلية.

على الرغم من أن التوجيه طلب إدخال كائن (كتاب) يختلف تمامًا عن الكائن الذي تم استبداله (جهاز الحاسب المحمول)، فقد قام النموذج بعمل جيد في مزج الأشكال والألوان؛ لإنشاء شكل بصري دقيق، ومع التقدم المستمر في تقنيات تعلم الآلة ورسومات الحاسب، من المحتمل أن نتمكن من إنشاء صور أكثر إبهارًا وواقعية في المستقبل.

يُمكنك مراجعة هذا القسم من الموضوع بعنوان “رسم صورة بالاسترشاد بنص” من خلال الرابط التالي:
اختبر تحصيلك لمحتوى الموضوع من خلال الرابط التالي:
الواجب الإلكتروني
إلى هنا يكون قد انتهى موضوع “توليد البيانات المرئية”، لا تنسوا مراجعة نواتج التعلُّم أعلى المقال، وانتظرونا في الموضوع القادم!